Introduzione
Quando Netscape diede il via al browser Mozilla, prese la decisione conscia di supportare gli standard W3C. Come risultato, Mozilla non è pienamente retrocompatibile con il vecchio codice di Netscape Navigator e Microsoft Internet Explorer; ad esempio, Mozilla non supporta <layer> come discuteremo in seguito. I browser, come Internet Explorer 4, realizzati prima della concezione degli standard W3C hanno ereditato molti comportamenti anomali (quirks). In questo articolo, descriveremo il quirks mode di Mozilla, che fornisce una forte retrocompatibiltà HTML con Internet Explorer ed altri browser datati.
Verranno considerate anche tecnologie non standard, come XMLHttpRequest ed il rich text editing, supportati da Mozilla perche' non esistevano all'epoca equivalenti del W3C. Esse includono:
- HTML 4.01, XHTML 1.0 eXHTML 1.1
- Fogli di stile (CSS): CSS Level 1, CSS Level 2.1 e parti del CSS Level 3
- Document Object Model (DOM): DOM Level 1, DOM Level 2 e parti di DOM Level 3
- Mathematical Markup Language: MathML Version 2.0
- Extensible Markup Language (XML): XML 1.0, Namespaces in XML, Associating Style Sheets with XML Documents 1.0, Fragment Identifier for XML
- XSL Transformations: XSLT 1.0
- XML Path Language: XPath 1.0
- Resource Description Framework: RDF
- Simple Object Access Protocol: SOAP 1.1
- ECMA-262, revision 3 (JavaScript 1.5): ECMA-262
Consigli generali di programmazione cross-browser
Anzhe se esistono gli standard Web, browser differenti si comportano in maniera differente (infatti, lo stesso browser potrebbe agire in modi diversi in base alla piattaforma). Molti browser, come Internet Explorer, supportano inoltre API precedenti a quelle definite dal W3C, e non hanno mai aggiunto un suporto estensivo per quelle definite dal W3C stesso.
Prima di entrare nello specifico delle differenze tra Mozilla ed Internet Explorer, verranno introdotti alcuni metodi base per rendere una applicazione Web estensibile in modo da aggiungere in un secondo momento il supporto per nuovi browser.
Poiché browser differenti a volte usano API differenti per le stesse funzionalità, di solito si trovano molti blocchi if() else() all'interno del codice per stabilire la differenza tra i vari browser. Il codice seguente mostra blocchi disegnati per Internet Explorer:
. . . var elm; if (ns4) elm = document.layers["myID"]; else if (ie4) elm = document.all["myID"]
Il codice appena visto non è estensibile, perciò se si vuole supportare un nuovo browser, bisogna necessariamente aggiornare questi blocchi all'interno dell'applicazione Web.
Il modo più semplice per eliminare il bisogno di riprogrammare per un nuovo browser è asttrarre le funzionalità. Piuttosto di molteplici blocchi if() else(), è possibile aumentare l'efficienza prendendo le azioni comuni e ed astraendole dalle proprie funzioni. Non solo questeo rende il codice più facile da leggere, semplifica l'aggiunta del supporto per nuovi client:
var elm = getElmById("myID");
function getElmById(aID){
var element = null;
if (isMozilla || isIE5)
element = document.getElementById(aID);
else if (isNetscape4)
element = document.layers[aID];
else if (isIE4)
element = document.all[aID];
return element;
}
Il codice soprastante ha ancora il problema del browser sniffing, o le rilevazione del browser che l'utente sta usando. Il browser sniffing viene solitamente eseguito attraverso lo useragent, come ad esempio:
Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.5) Gecko/20031016
Mentre l'uso dell'useragent per rilevare il browser fornisce dettagliate informazioni sul browser in uso, il codice che gestisce gli useragent è soggetto ad errori nel momento in cui arrivano nuove versioni di un browser, il che richiede un cambiamento nel codice.
Se il tipo di browser non è importante (supponiamo siano stati già bloccati i browser non supportati dall'accesso all'applicazione Web), è molto meglio e più sicuro rilevare le funzionalità del browser o il supporto di caratteristiche degli oggetti. Solitamenre è possibile fare questo testando le funzionalità richieste in JavaScript. Ad esempio, piuttosto che:
if (isMozilla || isIE5)
Si preferisce usare:
if (document.getElementById)
Questo potrebbe permettere ad altri browser che supportano i metodi standard del W3C, come Opera o Safari, di funzionare senza altri cambiamenti.
Lo sniffing dello useragent, in ogni caso, ha senso quando è importante l'accuratezza, ad esempio quando si sta verificando che un browser venga incontro ai requisiti di versione dell'applicazione Web o si sta provando ad evitare un bug.
JavaScript permette inoltre l'uso di statement condizionali abbreviati, il che può semplificare la leggibilità del codice:
var foo = (condition) ? conditionIsTrue : conditionIsFalse;
Ad esempio, per ottenere un elemento, è possibile usare:
function getElement(aID){
return (document.getElementById) ? document.getElementById(aID)
: document.all[aID]);
}
Oppure un'altra maniera è l'uso dell'operatore ||:
function getElement(aID){
return (document.getElementById(aID)) || document.all[aID]);
}
Differenze tra Mozilla e Internet Explorer
Anzitutto, discuteremo le differenze nel modo in cui HTML lavora tra Mozilla ed Internet Explorer.
Tooltip
I browser più datati hanno introdotto i tooltip in HTML mostrandoli sui link ed usando il valore dell'attributo alt come contenuto del tooltip. Le ultile specifice del W3C hanno dato vita all'attributo title, che serve per contenere una dettagliata descrizione del link. I browser moderni useranno l'attributo title per mostrare i tooltip, e Mozilla supporta solo la visualizzazione dei tooltip per questo attributo e non per alt.
Entità
Il marcatore HTML può contenere molte entità, come definito dal W3C web standards body. Le entità possono essere riferite attraverso il loro riferimento numerico o a caratteri. Ad esempio, è possibile riferire il carattere di spazio bianco #160 con  , o con il suo equivalente riferimento a caratteri .
Alcuni browser più vecchi, come Internet Explorer, hanno comportamenti strani che permettono l'uso di entità sostituendo il carattere ; (punto e virgola) alla fine con del testo normale:
  Foo    Foo
Mozilla interpreterà il precedente   con spazi bianchi, anche se contro le specifiche W3C. Il browser non effettuerà il parsing di un   se è direttamente seguito da più caratteri, come ad esempio:
 12345
Questo codice non funziona in Mozilla, poiché contro gli standard web del W3C. Per evitare discrepanze, è buona norma usare sempre la forma corretta ( ).
Differenze del DOM
Il Document Object Model (DOM) è la 'struttura ad albero che contiene gli elemendi del documento. Si può manipolarlo tramite le API JavaScript, che il W3C ha reso standard. In ogni caso, prima della standardizzazione del W3c, Netscape 4 ed Internet Explorer 4 implementavano delle API simili. Mozilla implementa solo le vecchie API che non sono riprodotte dagli standard W3C
Accedere agli elementi
Per ottenere un riferimento ad un elemento usando l'approccio cross-browser, si utilizza document.getElementById(aID), che funziona in Internet Explorer 5.0 e superiori, nei browser basati su Mozilla, altri browser che si attengono allo standard W3C ed è parte delle specifiche DOM Level 1.
Mozilla non supporta l'accesso agli elementi attraverso document.elementName o anche tramite il nome dell'elemento, come accade in Internet Explorer (una pratica chiamata anche inquinamento globale dei namspace). Mozilla inoltre non supporta il metodo document.layers di Netscape 4 né il document.all di Internet Explorer. Mentre document.getElementById permette di ottenere un elemento, si possono usare document.layers e document.all per avere una lista di tutti gli elementi del documento con un certo tag, come ad esempio tutti gli elementi <div>.
I metodi del DOM Level 1 del W3c fanno riferimento a tutti gli elementi con lo stesso tag attraverso getElementsByTagName(). Il metodo ritorna un array in JavaScript, e può essere chiamato sull'elemento document o altri nodi per cercare solo un il loro sottoalbero. Per ottenenere un array di elementi nell'albero DOM, è possibile usare getElementsByTagName("*").
Come mostrato nella Tabella 1, i metodi del DOM Level1 sono comunemente usati per muovere un elemento da una certa posizione e cambiare la sua visibilità (menu, animazioni). Netscape 4 usava il tag <layer>, che non è supportato da Mozilla, dato che un elemento HTML può essere posizionato ovunque. In Mozilla, è possibile posizionare ogni elemento usando il tag <div>, che usa anche Internet Esplorer e che si trova nella specifica di HTML.
| Metodo | Descrizione |
|---|---|
| document.getElementById( aId ) | Ritorna un riferimento all'elemento con l'ID specificato. |
| document.getElementsByTagName( aTagName ) | Ritorna un array di elementi avebti il nome specifico nel documento. |
Attraversare il DOM
Mozilla supporta le API DOM W3C per attraversare l'albero DOM tramite JavaScript (vedi Tabella 2). Le API esistono per ogni nodo nel documento e permettono di esplorare l'albero in ogni direzione. Anche Internet Explorer supporta queste API, ma support anche le sue vecchie API per per l'esplorazione dell'albero DOM, come la proprietà children
| Proprietà/Metodo | Descrizione | ||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| childNodes | Ritorna un array di tutti i nodi figli child dell'elemento. | ||||||||||||||||||||||||||
| firstChild | Ritorna il primo nodo figlio dell'elemento. | ||||||||||||||||||||||||||
| getAttribute( aAttributeName ) | Ritorna il valore per l'attributo specifico. | ||||||||||||||||||||||||||
| hasAttribute( aAttributeName ) | Ritorna un valore booleano indicante se il nodo corrente ha un attributo definito con il nome specifico. | ||||||||||||||||||||||||||
| hasChildNodes() | Ritorna un valore booleano se il nodo corrente ha nodi figli. | ||||||||||||||||||||||||||
| lastChild | Ritorna l'ultimo nodo figlio dell'elemento. | ||||||||||||||||||||||||||
| nextSibling | Ritorna il nodo immediatamente seguente a quello considerato. | ||||||||||||||||||||||||||
| nodeName | Ritorna il nome del nodo in forma di stringa. | ||||||||||||||||||||||||||
| nodeType | Ritorna il tipo del nodo corrente.
|
||||||||||||||||||||||||||
| nodeValue | Ritorna il valore del nodo corrente. Per nodi che contengono testo, ad esempio nodi text e comment, ritorna il loro valore in stringa. Per nodi attribute, viene ritornato il valore dell'attributo. Per tutti gli altri nodi, viene ritornato null. |
||||||||||||||||||||||||||
| ownerDocument | Ritorna l'oggetto document contenente il nodo corrente. |
||||||||||||||||||||||||||
| parentNode | Ritorna il nodo padre del nodo corrente. | ||||||||||||||||||||||||||
| previousSibling | Ritorna il nodo immediatamente precedente a quello corrente. | ||||||||||||||||||||||||||
| removeAttribute( aName ) | Rimuove l'attributo specificato dal nodo corrente. | ||||||||||||||||||||||||||
| setAttribute( aName, aValue ) | Setta il valore dell'attributo specificato con il valore specificato. |
Internet Explorer ha un comportamento non standard, dove molte delle API vanno ad evitare i nodi di spazi bianchi che sono generati, ad esempio, da caratteri di ritorno a capo. Mozilla non li evita, per questo alcune volte si ha bisogno di distinguere questi nodi. Ogni nodo ha una propietà nodeType che specifica il tipo di nodo. Ad esempio, un nodo element ha tipo 1, mentre un nodo text ha tipo 3 ed un nodo comment è di tipo 8. Il modo migliore per processare solo i nodi elemento è iterare su tutti i nodi figli e processare solo quelli con un nodeType di 1:
HTML:
<div id="foo">
<span>Test</span>
</div>
JavaScript:
var myDiv = document.getElementById("foo");
var myChildren = myXMLDoc.childNodes;
for (var i = 0; i < myChildren.length; i++) {
if (myChildren[i].nodeType == 1){
// element node
};
};
Generare e manipolare contenuto
Mozilla supporta i metodi più datati per aggiungere dinamicamente contenuto al DOM, come document.write, document.open w document.close. Mozilla supporta inoltre il metodo di Internet Explorer innerHTML, che può essere richiamato su quasi tutti i nodi. Non supporta outerHTML (che aggiunge marcatori intorno all'elemento e non ha equivalenti standard) e innerText (che modifica il valore del testo del nodo ed il cui comportamento viene ripreso in Mozilla usando textContent).
Internet Explorer ha diversi metodi per la manipolazione del contenuto che non sono né standard né supportati da Mozilla, incluso la ricezione del valore, l'inserimento di testo e di elementi adiacenti ad un nodo, come getAdjacentElement e insertAdjacentHTML. La Tabella 3 mostra i modi con cui standard W3C e Mozilla manipolano il contenuto, ognuno dei quali è metodo di un nodo DOM.
| Metodo | Descrizione |
|---|---|
| appendChild( aNode ) | Crea un nuovo nodo figlio. Ritorna un riferimento al nuovo nodo figlio. |
| cloneNode( aDeep ) | Crea una copia del nodo sul quale viene chiamato e ritorna la copia. Se aDeep è true, la copia viene estesa all'intero sottoalbero del nodo. |
| createElement( aTagName ) | Crea e ritorna un nuvo nodo DOM senza genitori, del tipo specificato da aTagName. |
| createTextNode( aTextValue ) | Crea e ritorna un nuovo nodo di testo DOM senza genitori, con il valore specificato da aTextValue. |
| insertBefore( aNewNode, aChildNode ) | Inserisce aNewNode prima di aChildNode, il quale deve essere figlio del nodo corrente. |
| removeChild( aChildNode ) | rimuove aChildNode e ritorna un riferimento ad esso |
| replaceChild( aNewNode, aChildNode ) | Sostituisce aChildNode con aNewNode e ritorna un riferimento al nodo rimosso. |
Frammenti del documento
per ragioni di performance, è possibile creare il documento in memoria piuttosto che lavorare nel DOM del documento esistente. La specifica DOM Level 1 Core ha introdotto i document fragments (frammenti di documento), ovvero documenti leggeri che contengono un sottoinsieme della normale interfaccia del documento. Ad esempio, getElementById non esiste, al contrario di appendChild. Inoltre è possbile aggiungere facilmente frammenti di documento al documento esistente.
Mozilla crea frammenti i documento attraverso document.createDocumentFragment(), che ritorna un frammento vuoto.
L'implementazione di Internet Explorer dei frammenti, comunque, non si attiene allo standard web del W3C e semplicemente ritorna un documento regolare.
Differenze di JavaScript
Molte differenze tra Mozilla e Internet Explorer sono solitamente notate in JavaScript. IN ogni caso, ilproblema risiede solitamente nelle API che un browser fornisce a JavaScript, come ad esempio gli agganci al DOM. I due browser possiedono alcune differenze nel linguaggio JavaScript stesso; i problemi incontrati sono spesso legati a fattori temporali.
Differenza di Date in JavaScript
L'unica differenza di Date è il metodo getYear. Secondo le specifiche ECMAScript (che sono le specifiche seguite da JavaScript), il metodo non è Y2k-compliant, e l'esecuzione di new Date().getYear() nel 2004 ritorna "104". Per la specifica ECMAScript, getYear ritorna l'anno meno 1900, originariamente inteso come "98" per "1998". getYear è assunto come deprecato nella versione 3 di ECMAScript ed è sostituito da getFullYear(). Internet Explorer ha modificato getYear() in modo da funzionare nella stessa maniera di getFullYear() rendendolo Y2K-compliant, mentre Mozilla ha mantenuto il metodo standard.
Differenze nell'esecuzione di JavaScript
Browser differenti eseguono JavaScript in maniera differente. Ad esempio, il codice seguente assume che il nodo div esista al momento in cui il blocco di codice script viene eseguito:
...
<div id="foo">Loading...</div>
<script>
document.getElementById("foo").innerHTML = "Done.";
</script>
Ovviamente, ciò non è garantito. Per assicurarsi che l'elemento esisya, è necessario usare il gestore di evento onload nel tag <body>:
<body onload="doFinish();">
<div id="foo">Loading...</div>
<script>
function doFinish() {
var element = document.getElementById("foo");
element.innerHTML = "Done.";
}
</script>
...
Problemi collegati al tempo sono inoltre legati all'hardware -- sistemi più lenti possono manifestare dei bug che invece sistemi più veloci nascondono. Un esempio concreto è window.open, che apre una nuova finestra:
<script>
function doOpenWindow(){
var myWindow = window.open("about:blank");
myWindow.location.href = "https://www.ibm.com";
}
</script>
Il problema con il codice è dato dal fatto che window.open è asincrona -- non blocca l'esecuzione di JavaScript finché la finestra non ha terminato il caricamento. Per questo, è possibile eseguire le linee di codice dopo window.open anche prima che la nuova finestra abbia terminato. Si può cercare di risolvere il problema usando un gestore onload nella nuova finestra e quindi tornare indietro alla finestra progenitrice (usando window.opener)
Differenza nella generazione di HTML con JavaScript
Javascript può, attraverso document.write, generare HTML al volo da una stringa. Il primo problema qui si ha quando JavaScript, inserito all'interno del documento HTML (cioè all'interno dei tag <script>), genera HTML che contiene un tag <script>. Se il documento è nel modo di impaginazione strict, verrà effettuato il parsing di <script> all'interno della stringa fino al tag di chiusura di <script>. Il codice seguente illustra meglio questa situazione:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"https://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
...
<script>
document.write("<script type='text\/javascript'>alert('Hello');<\/script>")
</script>
Dato che la pagina è in modo strict, il parser di Mozilla vedrà prima <script> ed effettuerà il parsing fino a trovare un tag di chiusura, che sarà la prima occorrenza di </script>. Questo perché il parser non è a conoscenza di JavaScript (o altri linguaggi) nella modalità strict. Nel modo quirks, il parser tiene conto di JavaScript nella sua esecuzione (il che lo rallenta). Internet Explorer è sempre in modalità quirks, poiché non supporta veramente XHTML. Per fare in modo che il funzionamento sia lo stesso in Mozilla, basta separare la stringa in due parti:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"https://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
...
<script>
document.write("<script type='text\/javascript'>alert('Hello');</" + "script>")
</script>
Debug di JavaScript
Mozilla fornisce diversi modi per il debugging di problemi legati a JavaScript trovati in applicazioni create per Internet Explorer. Il primo strumento è la console JavaScript integrata, mostrata in figura 1, dove errori ed avvertenze sono registrate. Vi si può accedere in Mozilla andando su Tools -> Web Development -> JavaScript Console o in Firefox (il prodotto solo browser di Mozilla) da Tools -> JavaScript Console.
Figura 1. console JavaScript
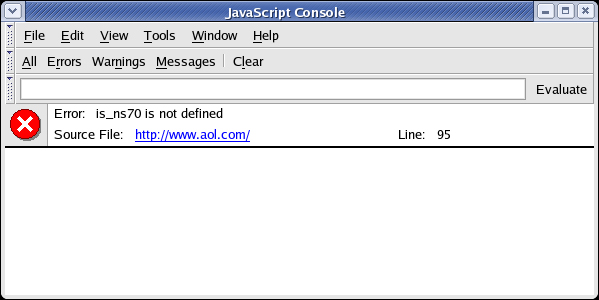
La console JavaScript può mostrare l'intera lista registrata o solamente errori, avvertenze e messaggi. Il messaggio di errore in Figura 1 indica che, su aol.com, la linea 95 prova ad accedere ad una variabile non definita chiamata is_ns70. Cliccando sil link si apre la finestra di visualizzazione sorgente di Mozilla con la riga interessata dall'errore evidenziata.
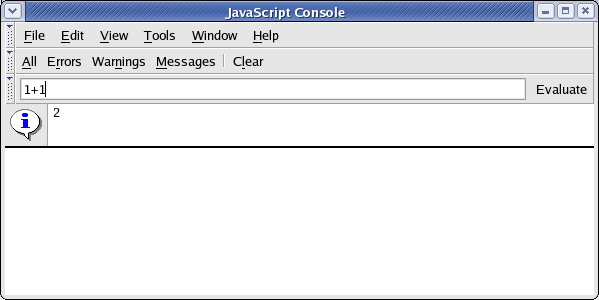
La console permette inoltre di valutare espressioni JavaScript. Per fare una prova della sinatssi JavaScript, inserire 1+1 nel campo di input e premere Evaluate,come mostrato dalla Figura 2.
Figura 2. valutazione di codice JavaScript
Il motore JavaScript di Mozilla ha un supporto integrato per il debugging, ovvero fornisce strumenti potenti per gli sviluppatori JavaScript. Venkman, mostrato nella Figura 3, è un potente debugger JavaScript multipiattaforma integrato con Mozilla. usualmente viene incluso insieme con le varie release di Mozilla; si può trovare in Tools -> Web Development -> JavaScript Debugger. Firefox non include ill debugger; invece, si può installarlo dalla pagina del progetto Venkman. Sono disponibili anche dei tutorial nella pagina di sviluppo, situati nella pagina di sviluppo Venkman.
Figura 3. Debugger JavaScript di Mozilla
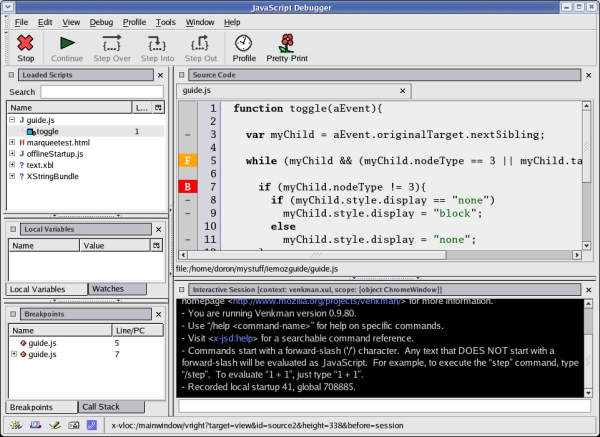
Il debugger JavaScript può effettuare il debug di JavaScript in esecuzione nella finestra browser di Mozilla. Supporta molte caratteristiche standard per il debugging, come la gestione breakpoint, l'inspezione dello stack di chiamata, e l'ispezione di variabile/oggetto. Tutte le caratteristiche sono accedibili attraverso l'interfaccia utente oppure tramite la console interattiva del debugger. Con la console, può essere eseguito codice JavaScript arbitrario nello stesso scope del codice JavaScript in corso di debugging.
Differenze sui CSS
I prodotti basati su Mozilla hanno il più forte supporto per i fogli di stile a cascata (CSS), inclusi la gran parte di CSS1, CSS2.1 e parti di CSS3, in rapporto ad Internet Explorer così come con altri browser.
Per molti dei problemi menzionati sotto, Mozilla aggiunge una riga di errore o di avvertenza nella console JavaScript. Per problemi legati a CSS, è sufficiente quindi controllare la console JavaScript.
Mimetypes (Quando i file CSS non vengono applicati)
Il più comune problema legato ai CSS è dato dal fatto che le definizioni dei CSS all'interno di file CSS referenziati non vengono applicate. Questo solitamente a causa del server che invia un errato mimetype per il file CSS. Le specifiche CSS indicano che il file CSS deve essere servito con il tipo mime text/css. Mozilla rispetta questa indicazione e carica solo file CSS con questo mimetype se la pagina web è visualizzata con in modalità strettamente standard. Internet Explorer carica sempre il file CSS, senza tenere conto del mimetype con il quale viene servito. Le pagine web vengono considerate nel modo strettamente standard quando iniziano con un doctype strict. Discuteremo dei doctype nella sezione seguente.
CSS e unità
Molte applicazioni web non usano unità con i propri CSS, specialmente se viene utilizzato Javascript per impostare i CSS. Mozilla tollera questo comportamento, nel momento in cui la pagina non viene visualizzata nel modo strict. Poiché Internet Explorer non supporta XHTML, non considera per niente se vengono specificate delle unità. Se la pagina è in modo strettamente standard, e nessuna unità viene usata, Mozilla ignora lo stile:
<DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "https://www.w3.org/TR/html4/strict.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1"> <title>CSS and units example</title> </head> <body> // works in strict mode <div style="width: 40px; border: 1px solid black;"> Text </div> // will fail in strict mode <div style="width: 40; border: 1px solid black;"> Text </div> </body> </html>
Dato che l'esempio mostrato ha un doctype strict, la pagina viene visualizzata con modo di impaginazione strettamente standard. Il primo div ha una lunghezza di 40px, poiché usa una unità, ma il secondo div non avrà una lunghezza, cioè tornerà alla lunghezza di default di 100%, la qual cosa accadrebbe se la stessa lunghezza fosse impostata tramite JavaScript.
JavaScript e CSS
Dato che Mozilla supporta gli standard CSS, supporta inoltre lo standard DOM CSS per impostare i CSS attraverso JavaScript. Si può accedere, rimuovere e cambiare la regola di un elemento CSS attraverso il membro style dell'elemento:
<div id="myDiv" style="border: 1px solid black;">
Text
</div>
<script>
var myElm = document.getElementById("myDiv");
myElm.style.width = "40px";
</script>
In questo modo si può raggiungere ogni attributo CSS. Ancora, se la pagina Web è in modo strict, va impostata una unità o Mozilla ignorerà il comando. Nella richiesta di un valore, diciamo per .style.width, in Mozilla ed Internet Explorer, il valore ritornato conterrà l'unità, il che implica il ritorno di una stringa. La stringa può essere convertita attraverso parseFloat("40px").
Differenze nell'overflow dei CSS
CSS aggiunge la nozione di overflow (traboccamento), che permette di definire come gestire un traboccamento; ad esempio, quando il contenuto di un div con una specifica altezza risulta più alto. Lo standard CSS definisce che se non è impostato alcun comportamento nel caso di overflow, il contenuto del div traboccherà dallo stesso. In ogni caso, Internet Explorer non rispetta questa indicazione e va ad espandere il div oltre l'altezza impostata per poter riprendere il contenuto. Sotto un esempio che mostra la differenza:
<div style="height: 100px; border: 1px solid black;">
<div style="height: 150px; border: 1px solid red; margin: 10px;">
a
</div>
</div>
Come si vede dalla Figura 4, Mozilla agisce secondo le specifiche dello standard W3C. Lo standard dice che, in questo caso, il div interno trabocca verso il basso poiché il suo contenuto ha una maggiore altezza relativa al suo contenitore. Se si preferisce il comportamento di Internet Explorer, semplicemente non va specificata alcuna altezza per l'elemento esterno.
Figura 4. overflow DIV
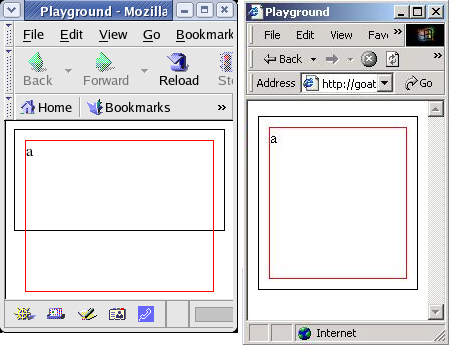
differenza di hover
Il comportamento non standard del selettore hover in Internet Exloprer si può riconoscere in diversi siti web. Usualmente si manifesta cambiando lo stile del testo se attraversato dal mouse con Mozilla, ma non con Internet Explorer. Questo perché il selettore a:hover in Internet Explorer considera <a href="">...</a> ma non <a name="">...</a>, che imposta una ancora in HTML. Il cambio di testo avviene perché gli autori incapsulano l'area con un marcatore di impostazione ancora:
CSS:
a:hover {color: green;}
HTML:
<a href="foo.com">This text should turn green when you hover over it.</a>
<a name="anchor-name">
This text should change color when hovered over, but doesn't
in Internet Explorer.
</a>
Mozilla segue le specifiche CSS correttamente e cambia il colore in verde in questo esempio. SI possono usare due maniere per far agire Mozilla come Internet Explorer a non cambiare il colore del testo al passaggio del mouse:
- In primo luogo, è possibile cambiare la regola CSS in
a:link:hover {color: green;}, che cambierà solo il colore se l'elemento è un link (ha un attributohref). - Alternativamente, si può cambiare il marcatore e chiudere
<a />prima dell'inizio del testo -- in questo modo l'ancora continuerà a funzionare.
Quirks vs. modo standard
Le versioni più antiquate di alcuni browser, come Internet Exlporer 4, impaginano insernedo artefatti in determinate condizioni. Mentre Mozilla tende ad essere un browser aderente agli standard, fornisce tre modi per sopportare pagine Web meno recenti realizzate con in mente questi comportamenti particolari. Recapito e contenuto della pagina determinano quale modo sarà utilizzato. Mozilla indicherà il modo di impaginazione in View -> Page Info (o premendo Ctrl+I); Firefox lo mostrerà in Tools -> Page Info.
The mode in which a page is located depends on its doctype.
Un Doctype (abbreviazione per document type declaration) è simile a questo:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "https://www.w3.org/TR/html4/loose.dtd">
La sezione in blu viene chiamata identificatore pubblico (public identifier), la parte vedere è l'identificatore di sistema (system identifier), nella forma di URI.
Modo standard
Il modo standard di impaginazione è qullo più restrittivo -- l'impaginazione avviene attenendosi alle specifiche HTML e CSS del W3C e non saranno supportati artefatti. Mozilla lo utilizza alle seguenti condizioni:
- se una pagina viene inviata con un mimetype
text/xmlo altri XML o XHTML, - per ogni doctype "DOCTYPE HTML SYSTEM" (ad esempio,
<!DOCTYPE HTML SYSTEM "https://www.w3.org/TR/REC-html40/strict.dtd">), ad eccezione del doctype IBM, - per doctype sconosciuti o doctype privi di DTD.
Modo quasi standard
Mozilla ha introdotto il modo quasi standard (almost standard mode) per una ragione: una sezione nella specifica CSS 2 rompe i design basati su un preciso schema fatto di piccole immagini in celle di tabelle. Invece di fornire una immagine intera all'utente, ogni piccola immagine finisce con un piccolo spazio a seguire. La vecchia homepage IBM mostrata in Figura 5 offre un esempio di questo comportamento.
Figura 5. Spazio tra immagini

Il modo quasi standard agisce quasi esattamente come il modo standard, fatta eccezione nel trattamento di immagini con un problema di spazio finale. Il problema occorre solitamente nelle pagine aderenti agli standard e causa la loro incorretta visualizzazione.
Mozilla usa il modo quasi standard alle seguenti condizioni:
- per ogni doctype "loose" (ad esempio,
<!DOCTYPE HTML PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN">,<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "https://www.w3.org/TR/html4/loose.dtd">), - per il doctype IBM
<!DOCTYPE html SYSTEM "https://www.ibm.com/data/dtd/v11/ibmxhtml1-transitional.dtd">)
Per altre informazioni, consultare l'articolo riguardante il problema di spazio tra immagini
Modo Quirks
Ad oggi, il Web è pieno di marcatori HTML invalidi, così come altri che funzionano solo a causa di bug di alcuni browser. I vecchi browser Netscape, nel periodo della loro leadership di mercato, contenevano bug. Quando fece il suo ingresso Internet Explorer, cercò di imitare gli stessi bug per poter funzionare con i contenuti dell'epoca. Con l'introduzione di nuovi browser nel mercato, molti di questi bug originali, solitamente chiamati quirks (artefatti), sono stati mantenuti per avere retrocompatibilità. Mozilla supporta molti di questi nel suo modo di impaginazione quirks. Si noti che a causa di questi artefatti, i documenti vengono impaginati più lentamente che se fossero stati aderenti agli standard. Molte pagine web sono trattate in questa maniera.
Mozilla usa il modo quirks alle seguenti condizioni:
- Quando non è specificato alcun doctype
- Per i doctype senza identificatore di sistema (ad esempio,
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">)
Per approfondimenti, si vedano: Funzionamento del Quirks Mode di Mozilla e Sniffing DOCTYPE di Mozilla
Differenze nella gestione eventi
Mozilla e Internet Explorer sono completamente differenti nell'area degli eventi Il modello eventi di Mozilla segue i modelli W3C e Netscale. In Internet Explorer, se una funzione viene chiamata tramite evento, ha accesso all'oggetto event attraverso window.event Mozilla passa un oggetto event ai gestori di eventi, i quali devono specificatamente passare l'oggetto alla funzione chiamata tramite un argomento.
Ecco un esempio di gestione cross-browser (nota: implica l'impossibilità di definire una vasriabile globale chiamata event nel proprio codice):
<div onclick="handleEvent(event);">Click me!</div>
<script>
function handleEvent(aEvent) {
var myEvent = window.event ? window.event : aEvent;
}
</script>
Funzioni e proprietà esposte dell'oggetto event sono solitamente chiamate in maniera differente in Mozilla e Internet Explorer, come mostrato dalla Tabella 4.
| Nome Internet Explorer | Nome Mozilla | Descrizione |
|---|---|---|
| altKey | altKey | Proprietà booleana ritornata in caso di pressione del tasto ALT durante l'evento. |
| cancelBubble | stopPropagation() | Usata per fermate la propagazione dell'evento verso la radice dell'alberoUsed to stop the event. |
| clientX | clientX | Ordinata dell'evento, in relazione al viewport dell'elemento. |
| clientY | clientY | Ascissa dell'evento, in relazione al viewport dell'elemento. |
| ctrlKey | ctrlKey | proprietà ritornata in caso di pressione del tasto CTRL durante l'evento. |
| fromElement | relatedTarget | per eventi del mouse, l'elemento dal quale il mouse si è spostato. |
| keyCode | keyCode | Per eventi da tastiera, il numero che rappresentante il tasto premuto. Per eventi del mouse è 0. Per eventi keypress (non keyup o keydown) riguardanti tasti che producono output, l'equivalente Mozilla è charCode, non keyCode. |
| returnValue | preventDefault() | usato per prevenire l'esecuzione dell'azione di default dell'evento. |
| screenX | screenX | Ordinata dell'evento, in relazione allo schermo. |
| screenY | screenY | Ascissa dell'evento, in relazione allo schermo. |
| shiftKey | shiftKey | Proprietà booleana ritornata in caso di pressione del tasto SHIFT durante l'evento. |
| srcElement | target | Elemento dal quale l'evento ha avuto origine. |
| toElement | currentTarget | Per eventi del mouse, l'elemento verso il quale il mouse si è mosso. |
| type | type | Ritorna il nome dell'evento. |
Aggiungere gestori di eventi
Mozilla supporta due modi per aggiungere eventi attraverso JavaScript. Il primo, supportato da tutti i browser, imposta le proprietà event direttamente sugli oggetti. Per impostare un gestore di evento click, un riferimento di funzione viene passato alla proprietà onclick dell'oggetto:
<div id="myDiv">Click me!</div>
<script>
function handleEvent(aEvent) {
// if aEvent is null, means the Internet Explorer event model,
// so get window.event.
var myEvent = aEvent ? aEvent : window.event;
}
function onPageLoad(){
document.getElementById("myDiv").onclick = handleEvent;
}
</script>
Mozilla supporta pienamente il metodo standard del W3C di aggiungere dei listener (letterarmente ascoltatori) ai nodi DOM. L'uso dei metodi addEventListener() e removeEventListener() ha il beneficio di permettere l'impostazione di molteplici listener per lo stesso tipo di evento. Entrambi i metodi richiedono tre paramentri: Il tipo di evento, una riferimento a funzione, ed un valore booleano che indica se il listener debba o meno catturare eventi nella sua fase di cattura. Se il valore del booleano è false, verranno catturati solo gli eventi propagati. Gli eventi W3C hanno tre fasi: cattura (capturing), obbiettivo (at target) e propagazione (bubbling). Ogni oggetto evet ha un attributo eventPhase che indica la fase numericamente (a partire da 0). Ogni qualvolta viene eseguito un evento, esso parte dall'elemento più esterno del DOM, quello alla radice dell'albero DOM. L'evento poi viaggia all'interno del DOM usando il percorso più diretto verso l'obbiettivo, realizzando la fase di capturing. Appena arriva, l'evento si trova nella fase obbiettivo. Dopo il suo arrivo, effettua un nuovo viaggio nell'albero verso il nodo più esterno: la fase di propagazione. Il modello eventi di Internet Explorer ha solo la fase di propagazione; questo significa che impostare il terzo parametro come false equivale ad imitare il comportamento di Internet Explorer:
<div id="myDiv">Click me!</div>
<script>
function handleEvent(aEvent) {
// if aEvent is null, it is the Internet Explorer event model,
// so get window.event.
var myEvent = aEvent ? aEvent : window.event;
}
function onPageLoad() {
var element = document.getElementById("myDiv");
element.addEventListener("click", handleEvent, false);
}
</script>
Un vantaggio di addEventListener() e removeEventListener() rispetto ad impostare proprietà è la possibilità di impostare molteplici listener per lo stesso evento, ognuno dei quali richiama una funzione. Per questo la rimozione di un listener richiede che i tre parametri siano gli stessi usati per la sua aggiunta.
Mozilla non supporta il metodo di Internet Explorer di conversione dei tag <script> in gestori di event, che estende <script> con gli attributi for e event (vedi Tabella 5). Inoltre non supporta i metodi attachEvent e detachEvent. Al loro posto si consiglia l'utilizzo dei metodi addEventListener e removeEventListener. Internet Explorer non supporta le specifiche degli eventi del W3C
| Metodo Internet Explorer | Metodo Mozilla | Descrizione |
|---|---|---|
| attachEvent(aEventType, aFunctionReference) | addEventListener(aEventType, aFunctionReference, aUseCapture) | Aggiunge un listener di evento ad un elemento DOM. |
| detachEvent(aEventType, aFunctionReference) | removeEventListener(aEventType, aFunctionReference, aUseCapture) | Rimuove un listener di evento da un elemento DOM. |
Rich text editing
Mentre Mozilla si vanta di essere il milgior browser attinente agli standard W3C, supporta inoltre funzionalità standard, come innerHTML ed il rich text editing, nel momento in cui non esistenti equivalenti W3C.
Mozilla 1.3 ha introdotto una implementazione del designMode di Internet Explorer, che converte un documento HTML in un rich text editor. Una volta fatto questo, possono essere esguiti comandi attraverso il comando execCommand. Mozilla non supporta l'attributo contentEditable di Internet Explorer per rendere ogni widget modificabile. Si può usare un iframe per aggiungere un rich text editor.
Differenze nel Rich text
Mozilla supporta lo standard W3C per accedere all'oggetto document di un iframe attraverso IFrameElmRef.contentDocument, mentre Internet Explorer richiede l'accesso attraverso document.frames["IframeName"] e poi l'accesso al document risultante.
<script>
function getIFrameDocument(aID) {
var rv = null;
// if contentDocument exists, W3C compliant (Mozilla)
if (document.getElementById(aID).contentDocument){
rv = document.getElementById(aID).contentDocument;
} else {
// IE
rv = document.frames[aID].document;
}
return rv;
}
</script>
Un'altra differenza tra Internet Explorer e Mozilla è nell'HTML creato dal rich text editor. Mozilla usa come modo predefinito i CSS per i marcatori generati. In ogni caso, Mozilla permette anche di scegliere tra i modi HTML e CSS usando il comando execCommand useCSS e scegliendo tra i valori true e false. Internet Explorer usa sempre il modo HTML.
Mozilla (CSS): <span style="color: blue;">Big Blue</span> Mozilla (HTML): <font color="blue">Big Blue</font> Internet Explorer: <FONT color="blue">Big Blue</FONT>
Sotto una lista di comandi supportati in execCommand di Mozilla:
| Nome comando | Descrizione | Argomento |
|---|---|---|
| bold | Cambia l'attributo bold (grassetto) della selezione. | --- |
| createlink | genera un link HTML dal testo selezionato. | URL da usare per il link |
| delete | Cancella la selezione. | --- |
| fontname | Cambia il font usato nel testo selezionato. | Nome del font da usare (ad esempio Arial) |
| fontsize | Cambia la dimensione del font usato nel testo selezionato. | Dimensione da usare |
| fontcolor | Cambia il colore del font usato nel testo selezionato. | Colore da usare |
| indent | Indenta il blocco su cui è posizionato il cursore. | --- |
| inserthorizontalrule | Inserisce un elemeto <hr> alla posizione del cursore. | --- |
| insertimage | Inserisce una immagine alla posizione del cursore. | URL dell'immagine da usare |
| insertorderedlist | Inserisce un elemento di lista ordinata (<ol>) alla posizione del cursore. | --- |
| insertunorderedlist | Inserisce un elemento di lista non ordinata (<ul>) alla posizione del cursore. | --- |
| italic | Cambia l'attributo italic (corsivo) della selezione. | --- |
| justifycenter | Centra il contenuto della linea corrente. | --- |
| justifyleft | Giustifica il contenuto della linea corrente a sinistra. | --- |
| justifyright | Giustifica il contenuto della linea corrente a destra. | --- |
| outdent | Indenta all'indietro il blocco su cui è posizionato il cursore. | --- |
| redo | Riesegue un comando precedentemente annullato | --- |
| removeformat | Rimuove la formattazione del testo selezionato | --- |
| selectall | Seleziona tutto all'interno del rich text editor. | --- |
| strikethrough | Cambia l'attributo strikethrough (segnato) della selezione. | --- |
| subscript | Converte la selezione corrente in pedice. | --- |
| superscript | Converte la selezione corrente in apice. | --- |
| underline | Cambia l'attributo underline (sottolineato) della selezione. | --- |
| undo | Annulla l'ultimo comando eseguito | --- |
| unlink | Rimuove le informazioni di link del testo selezionato. | --- |
| useCSS | Cambia l'uso dei CSS nel marcatore generato | Valore booleano |
Per altre informazioni, consultare Rich-Text Editing in Mozilla.
Differenze in XML
Mozilla ha un robusto supporto per XML e tecnologie ad esso correlato, come XSLT e Web service. Supporta inoltrer alcune estensioni non standard di Internet Explorer, come XMLHttpRequest.
Come gestire XML
Come con lo standard HTML, Mozilla supporta le specifiche W3C XML DOM, che permettono di manipolare quasi ogni aspetto di un documento XML. Differenze tra il DOM XML in Internet Explorer e Mozilla sono solitamente causate da comportamenti non standard di Internet Explorer. Probabilmente la più comune è la gestione nodi di spazi bianchi. Solitamente un documento generato in XML contiene spazi tra i nodi XML. Internet Explorer, nell'uso di Node.childNodes, non contiene tali nodi di spazio. In Mozilla, questi nodi saranno contenuti nell'array.
XML:
<?xml version="1.0"?>
<myXMLdoc xmlns:myns="https://myfoo.com">
<myns:foo>bar</myns:foo>
</myXMLdoc>
JavaScript:
var myXMLDoc = getXMLDocument().documentElement;
alert(myXMLDoc.childNodes.length);
La prima linea di javaScript carica il documento XML ed accede all'elemento radice (myXMLDoc) usando documentElement. La seconda linea semplicemente annuncia il numero di nodi figli. Secondo le specifiche W3C, gli spazi bianchi ed i ritorno a capo si fondono in un solo nodo di testo, se essi si susseguono. Per Mozilla, il nodo myXMLdoc ha tre figli: un nodo testo contenente un ritorno a capo e due spazi; il nodo the myns:foo: ed un altro nodo di testo con un ritorno a capo. Internet Explorer, comunque, Internet Explorer non tollera questo e ritorna "1" per il codice soprastante, indicando solo il nodo myns:foo. Per questo, per scorrere gli elementi figli evitando i nodi testo, questi vanno identificati.
Come detto prima, ogni nodo ha una proprietà nodeType rappresentante il tipo di nodo. Ad esempio, un nodo element ha tipo1, mentre un nodo document ha tipo 9. Per evitare i nodi di testo, è sufficiente controllare i tipi 3 (nodo testo) e 8 (nodo commento).
XML:
<?xml version="1.0"?>
<myXMLdoc xmlns:myns="https://myfoo.com">
<myns:foo>bar</myns:foo>
</myXMLdoc>
JavaScript:
var myXMLDoc = getXMLDocument().documentElement;
var myChildren = myXMLDoc.childNodes;
for (var run = 0; run < myChildren.length; run++){
if ( (myChildren[run].nodeType != 3) &&
myChildren[run].nodeType != 8) ){
// not a text or comment node
};
};
Vedere Spazi nel DOM per una discussione dettagliata e possibili soluzioni.
Isole dati XML
Internet Explorer ha una caratteristica non standard chiamata Isole dati XML (XML data islands), che permette di integrare XML all'interno di tag di un documento HTML. La stessa funzionalità è raggiungibile tramite l'uso di XHTML: comunque, poiché il supporto ad XHTML di Internet Explorer è debole, questa non si rivela una opzione usuale.
IE XML data island:
<xml id="xmldataisland"> <foo>bar</foo> </xml>
Una soluzione cross-browser consiste nell'usare i parser DOM, che effettuano i parsing di una stringa che contiene un documento XML serializzato e generano il documento per l'XML sottoposto al parsing. Mozilla usa l'oggetto DOMParser, che prende una stringa serializzata e genera un documento da essa. Il codice seguente mostra come:
var xmlString = "<xml id=\"xmldataisland\"><foo>bar</foo></xml>";
var myDocument;
if (window.DOMParser) {
// This browser appears to support DOMParser
var parser = new DOMParser();
myDocument = parser.parseFromString(xmlString, "text/xml");
} else if (window.ActiveXObject){
// Internet Explorer, create a new XML document using ActiveX
// and use loadXML as a DOM parser.
myDocument = new ActiveXObject("Microsoft.XMLDOM");
myDocument.async = false;
myDocument.loadXML(xmlString);
} else {
// Not supported.
}
vedere Uso di Isole dati XML in Mozilla per un approccio alternativo.
XMLHttpRequest
Internet Explorer permette di inviare e ricevere file XML usando la classe MSXML XMLHTTP. Istanzata attraverso ActiveX usando new ActiveXObject("Msxml2.XMLHTTP") o new ActiveXObject("Microsoft.XMLHTTP"). Poiché non esiste metodo standard per fare questo, Mozilla fornisce la stessa funzionalità nell'oggetto globale XMLHttpRequest. Dalla versione 7 IE stesso supporta un oggetto XMLHttpRequest "nativo".
Dopo aver instanziato l'oggetto usando new XMLHttpRequest(), si può usare il metodo open per specificare il tipo di richiesta (GET o POST) da usare, quale file caricare, e l'asincronicità o meno della chiamata. Se la chiamata è asincrona, va dato un riferimento a funzione al membro onload, chiamato una volta completata la richiesta.
Synchronous request:
var myXMLHTTPRequest = new XMLHttpRequest();
myXMLHTTPRequest.open("GET", "data.xml", false);
myXMLHTTPRequest.send(null);
var myXMLDocument = myXMLHTTPRequest.responseXML;
Asynchronous request:
var myXMLHTTPRequest; function xmlLoaded() { var myXMLDocument = myXMLHTTPRequest.responseXML; } function loadXML(){ myXMLHTTPRequest = new XMLHttpRequest(); myXMLHTTPRequest.open("GET", "data.xml", true); myXMLHTTPRequest.onload = xmlLoaded; myXMLHTTPRequest.send(null); }
La Tabella 7 mostra a lista di metodi e proprietà disponibili per XMLHttpRequest di Mozilla.
| Nome | Descrizione | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| void abort() | Ferma la richiesta se ancora in esecuzione. | ||||||||||||
| string getAllResponseHeaders() | Ritorna tutte le intestazioni di risposta in un'unica stringa. | ||||||||||||
| string getResponseHeader(string headerName) | Ritorna il valore dell'intestazione specificata. | ||||||||||||
| functionRef onerror | Se impostata, la funzione riferita viene chiamata ogni qualvolta si presenta un errore durante la richiesta. | ||||||||||||
| functionRef onload | Se impostata, la funzione riferita viene chiamata quando la richiesta termina con successo e viene ricevuta la risposta. Metodo usato per richieste asincrone. | ||||||||||||
| void open (string HTTP_Method, string URL) void open (string HTTP_Method, string URL, boolean async, string userName, string password) |
Inizializza la richiesta per lo URL dato, usando uno dei metodi HTTP GET o POST. Per inviare la richiesta, viene chiamato il metodo send() dopo l'inizializzazione. Se async è false, la richiesta è sincrona, altrimento automaticamente asincrona. Opzionalmente, possono essere specificati username e password per lo URL se necessario. |
||||||||||||
| int readyState | Stato della richiesta. valori possibili:
|
||||||||||||
| string responseText | Stringa contenente la risposta. | ||||||||||||
| DOMDocument responseXML | DOM Document contenente la risposta. | ||||||||||||
| void send(variant body) | Inizia la richiesa. Se body è definito, viene inviato come corpo della richiesta POST. body puo essere un XML document o un XML document serializzato come stringa. |
||||||||||||
| void setRequestHeader (string headerName, string headerValue) | Imposta una intestazione HTTP da usare per la richista. Deve essere invocato dopo la chiamata di open(). |
||||||||||||
| string status | Codice di stato della risposta HTTP. |
Differenze in XSLT
Mozilla supporta XSL Transformations (XSLT) 1.0. Permette inoltre a JavaScript di eseguire trasformazioni XSLT e di eseguire XPath su un documento.
Mozilla richiede di inviare i file XML ed XSLT con un mimetype XML (text/xml or application/xml). Questa è la ragione più comune per cui XSLT solitamente non funziona con Mozilla ma funziona con Internet Explorer. Mozilla è molto esigente per questo.
Internet Explorer 5.0 e 5.5 supportano il working draft di XSLT, il quale è sostanzialmente differente dalla raccomandazione finale 1.0. Un semplice modo per distinguere quale versione viene utilizzata per scrivere un file XSLT è dato dal controllo del namespace. Il namespace per la raccomandazione 1.0 è https://www.w3.org/1999/XSL/Transform, mentre il namespace del draft è https://www.w3.org/TR/WD-xsl. Internet Explorer 6 supporta il draft per retrocompatibilità ma Mozilla non supporta il draft, ma solo la raccomandazione finale.
Se XSLT richiede l'identificazione del browser, è possibile interrogare la proprietà di sistema "xsl:vendor". Il motore XSLT di Mozilla dà come risposta "Transformiix", e Internet Explorer risponde "Microsoft".
<xsl:if test="system-property('xsl:vendor') = 'Transformiix'">
<!-- Mozilla specific markup -->
</xsl:if>
<xsl:if test="system-property('xsl:vendor') = 'Microsoft'">
<!-- Internet Explorer specific markup -->
</xsl:if>
Mozilla fornisce inoltre interfacce JavaScript per XSLT, permettendo ad un sito Web di completare trasformazioni XSLT in memoria, attraverso l'oggetto globale XSLTProcessor. XSLTProcessor richiede di caricare i file XML ed XSLT, in quanto necessita i loro DOM document. Il document XSLT, importato attraverso XSLTProcessor, permette di manipolare parametri XSLT.
XSLTProcessor può generare un documento a sé usando transformToDocument(), o creare un frammento di documento tramite transformToFragment(), che può essere facilmente aggiunto ad un altro document DOM. Un esempio sotto:
var xslStylesheet;
var xsltProcessor = new XSLTProcessor();
// load the xslt file, example1.xsl
var myXMLHTTPRequest = new XMLHttpRequest();
myXMLHTTPRequest.open("GET", "example1.xsl", false);
myXMLHTTPRequest.send(null);
// get the XML document and import it
xslStylesheet = myXMLHTTPRequest.responseXML;
xsltProcessor.importStylesheet(xslStylesheet);
// load the xml file, example1.xml
myXMLHTTPRequest = new XMLHttpRequest();
myXMLHTTPRequest.open("GET", "example1.xml", false);
myXMLHTTPRequest.send(null);
var xmlSource = myXMLHTTPRequest.responseXML;
var resultDocument = xsltProcessor.transformToDocument(xmlSource);
Dopo la creazione di un XSLTProcessor, è possibile caricare un file XSLT usando XMLHttpRequest. Il membro responseXML di XMLHttpRequest contiene il documento XML per il file XSLT, il quale viene passato importStylesheet. Si può ancora usare XMLHttpRequest per caricare il documento sorgente XML da trasformare; tale documento viene passato al metodo transformToDocument metodo di XSLTProcessor. La Tabella 8 mostra una lista di metodi XSLTProcessor.
| Method | Descrizione |
|---|---|
| void importStylesheet(Node styleSheet) | Importa il foglio di stile XSLT. L'argomento styleSheet è il nodo radice del documento DOM del foglio si stile XSLT. |
| DocumentFragment transformToFragment(Node source, Document owner) | Trasforma il nodo source applicando il foglio di stile importato tramite il metodo importStylesheet e genera un DocumentFragment. owner il documento DOM a cui DocumentFragment deve appartenere, permettendone l'aggiunta. |
| Document transformToDocument(Node source) | Trasforma il nodo source applicando il foglio di stile importato usando importStylesheet e ritorna un documento DOM a sé. |
| void setParameter(String namespaceURI, String localName, Variant value) | Imposta un parametro nel foglio di stile XSLT importato. |
| Variant getParameter(String namespaceURI, String localName) | Ritorna il valore di un parametro nel foglio di stile XSLT importato. |
| void removeParameter(String namespaceURI, String localName) | Rimuove tutti i valori impostati nel foglio di stile XSLT e riporta i parametri ai valori predefiniti |
| void clearParameters() | Removes all set parameters and sets them to defaults specified in the XSLT stylesheet. |
| void reset() | Rimuove tutti i parametri e fogli di stile. |
Original Document Information
- Author(s): Doron Rosenberg, IBM Corporation
- Published: 26 Jul 2005
- Link: https://www.ibm.com/developerworks/we...y/wa-ie2mozgd/