Introduction
Lorsque Netscape a débuté le projet Mozilla, la décision de suivre les standards du W3C a été prise en toute conscience. C'est la raison pour laquelle Mozilla n'est pas entièrement compatible avec le code anciennement conçu pour Netscape Navigator 4.x et Microsoft Internet Explorer. Par exemple, Mozilla ne reconnaît pas <layer> comme nous le verrons plus tard. Les navigateurs, comme Internet Explorer 4, qui ont été conçus avant la publication des standards du W3C ont hérité de nombreuses bizarreries. Nous parlerons dans cet article du mode quirks de Mozilla, qui offre une bonne compatibilité HTML ascendante avec Internet Explorer et d'autres anciens navigateurs.
Nous aborderons également certaines technologies non standard, comme XMLHttpRequest et l'édition de texte enrichi, que Mozilla supporte parce qu'aucun équivalent W3C n'existait à l'époque. Parmi les standards supportés, on peut citer :
- HTML 4.01, XHTML 1.0 et XHTML 1.1
- Les feuilles de style en cascade (CSS) : CSS Level 1, CSS Level 2.1 et certaines parties de CSS Level 3
- Le Document Object Model (DOM) : DOM Level 1, DOM Level 2 et certaines parties de DOM Level 3
- Mathematical Markup Language : MathML Version 2.0
- Extensible Markup Language (XML) : XML 1.0, les espaces de noms en XML, l'association de feuilles de style avec des documents XML 1.0, les identificateurs de fragments XML
- XSL Transformations : XSLT 1.0
- XML Path Language : XPath 1.0
- Resource Description Framework : RDF
- Simple Object Access Protocol : SOAP 1.1
- ECMA-262, troisième édition (JavaScript 1.5) : ECMA-262
Astuces générales de codage multinavigateur
Même si les standards du Web existent, des navigateurs différents se comporteront différemment (en réalité, le même navigateur peut se comporter différemment suivant la plateforme). De nombreux navigateurs, comme Internet Explorer, gèrent également des API plus anciennes que celles du W3C et le support complet de celles-ci n'a jamais été ajouté.
Avant de se plonger dans les différences entre Mozilla et Internet Explorer, voyons quelques manières de base de rendre une application Web extensible afin qu'elle puisse fonctionner dans de nouveaux navigateurs par la suite.
Puisque des navigateurs différents utilisent parfois des API différentes pour la même fonctionnalité, on trouvera souvent une série de blocs if() else() tout au long du code pour différentier les différents navigateurs. Le code qui suit montre des blocs conçus pour Internet Explorer :
. . . var elm; if (ns4) elm = document.layers["monID"]; else if (ie4) elm = document.all["monID"]
Ce code n'est pas extensible, par conséquent si l'on désire qu'il gère un nouveau navigateur, ces blocs doivent être mis à jour un peu partout dans l'application Web.
La manière la plus simple d'éliminer le besoin de recoder pour un nouveau navigateur est de rendre la fonctionnalité abstraite. Plutôt que d'utiliser une série de blocs if() else(), il sera plus performant d'extraire certaines tâches courantes et de les placer dans leurs propres fonctions. Non seulement le code en sera plus lisible, mais l'ajout de nouveaux clients en sera simplifié :
var elm = getElmById("myID");
function getElmById(aID){
var element = null;
if (isMozilla || isIE5)
element = document.getElementById(aID);
else if (isNetscape4)
element = document.layers[aID];
else if (isIE4)
element = document.all[aID];
return element;
}
Ce code a toujours un problème, c'est qu'il utilise un « sniffing » du navigateur, c'est-à-dire qu'il détecte le navigateur utilisé par l'utilisateur. Le sniffing est généralement fait sur la chaîne d'agent utilisateur (useragent), comme celle-ci :
Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.5) Gecko/20031016
Bien que l'utilisation de la chaîne useragent pour détecter le navigateur fournisse un bon nombre d'informations détaillées sur le navigateur utilisé, le code de gestion de ces chaînes peut souvent faire des erreurs lorsque de nouvelles versions de ces navigateurs font leur apparition, ce qui oblige à modifier le code.
Si le type de navigateur n'a pas d'importance (supposons que l'accès à l'application Web ait déjà été bloqué aux navigateurs non supportés), il est nettement plus sûr et efficace de vérifier le support de capacités ou d'objets particuliers du navigateur. Cela peut généralement être réalisé en testant la fonctionnalité requise en JavaScript. Par exemple, plutôt que :
if (isMozilla || isIE5)
On peut utiliser :
if (document.getElementById)
Cela permettra à d'autres navigateurs supportant cette méthode standard du W3C, comme Opera ou Safari, de fonctionner sans aucun changement.
Le sniffing de la chaîne useragent reste cependant approprié lorsque la précision est importante, comme la vérification qu'un navigateur soit d'une version suffisante pour accéder à votre application Web ou si vous essayez de contourner un bug connu.
JavaScript permet également d'utiliser des instructions conditionnelles en une ligne, qui peuvent rendre le code plus lisible :
var test = (condition) ? laConditionEstVraie : laConditionEstFausse;
Par exemple, pour retrouver un élément, on peut utiliser :
function getElement(aID){
return (document.getElementById) ? document.getElementById(aID)
: document.all[aID]);
}
Une autre manière est d'utiliser l'opérateur || :
function getElement(aID){
return (document.getElementById(aID)) || document.all[aID]);
}
Différences entre Mozilla et Internet Explorer
Pour commencer, nous parlerons des différences entre la manière dont HTML se comporte dans Mozilla et dans Internet Explorer.
Bulles d'information
Les premiers navigateurs ont introduit les bulles d'information en HTML en les montrant sur les liens et en utilisant la valeur de l'attribut alt d'une image comme contenu de cette bulle. Les spécifications HTML du W3C ont cependant créé l'attribut title, prévu pour contenir une description détaillée du lien. Les navigateurs modernes utiliseront cet attribut title pour afficher des bulles d'information, et Mozilla ne les affichera que pour cet attribut, jamais pour l'attribut alt.
Entités
Le balisage HTML peut contenir plusieurs entités, qui ont été définies par le W3C. Celles-ci peuvent être référencées par leur valeur numérique ou par une chaîne de caractères. Par exemple, le caractère d'espacement #160 peut être référencé par   ou par sa référence en caractères équivalente .
Certains navigateurs plus anciens, comme Internet Explorer, permettaient d'utilisation des entités sans le caractère ; (point-virgule) à la fin :
  Foo    Foo
Mozilla affichera les   ci-dessus comme des espaces, même si c'est à l'encontre des spécifications du W3C. Le navigateur ne traitera par contre pas un   s'il est directement suivi d'autres caractères, par exemple :
 12345
Ce dernier code ne fonctionnera pas dans Mozilla, puisqu'il ne respecte absolument pas les standards du W3C. Utilisez toujours la forme correcte ( ) pour éviter les différences de traitement entre les navigateurs.
Différences dans le DOM
Le Document Object Model (DOM) est la structure arborescente contenant les éléments du document. Celle-ci peut être manipulée au travers d'API JavaScript qui ont été standardisées par le W3C. Cependant, avant cette standardisation, Netscape 4 et Internet Explorer 4 avaient déjà implémenté des API similaires. Mozilla n'implémente ces anciennes API que si elles ne sont pas réplicables avec les standards Web du W3C.
Accès aux éléments
Pour obtenir une référence à un élément en utilisant une approche multinavigateur, on utilise document.getElementById(aID) qui fonctionne dans Internet Explorer 5.0+, les navigateurs basés sur Mozilla, les autres navigateurs suivant le W3C et fait partie de la spécification DOM Level 1.
Mozilla ne permet pas d'accéder à un élément via document.elementName ou même par le nom d'un élément, ce que fait Internet Explorer (et qu'on peut appeler pollution de l'espace de noms global). Mozilla ne permet pas non plus d'utiliser les méthodes document.layers de Netscape et document.all d'Internet Explorer. Alors que document.getElementById permet de trouver un seul élément, document.layers et document.all servaient également à obtenir une liste de tous les éléments portant un certain nom de balise, comme tous les éléments <div>.
La méthode du DOM Level 1 du W3C obtient les références de tous les éléments portant le même nom de balise par getElementsByTagName(). Cette méthode renvoie un tableau en JavaScript, et peut également être appelée sur l'élément document ou sur d'autres nœuds pour chercher uniquement parmi leurs descendants dans l'arbre. Pour obtenir un tableau de tous les éléments dans l'arbre DOM, on peut utiliser getElementsByTagName("*").
Les méthodes du DOM Level 1, telles que montrées dans le Tableau 1, sont souvent utilisées pour déplacer un élément à un certain endroit et modifier sa visibilité (menus, animations). Netscape 4 utilisait la balise <layer>, qui n'est pas reconnue par Mozilla, comme élément HTML pouvant être positionné n'importe où. Dans Mozilla, n'importe quel élément utilisant la balise <div> peut être repositionné, ce qui est également utilisé par Internet Explorer et figure dans la spécification HTML.
| Méthode | Description |
|---|---|
document.getElementById(unID) |
Renvoie une référence à l'élément portant l'ID spécifié. |
document.getElementsByTagName(nomBalise) |
Renvoie un tableau des éléments portant le nom spécifié dans le document. |
Parcours du DOM
Mozilla supporte les API du DOM W3C pour le parcours de l'arbre DOM depuis JavaScript (voir le Tableau 2). Ces API existent pour chaque nœud dans le docment et permettent de parcourir l'arbre dans toutes les directions. Internet Explorer supporte également ces API, outre ses anciennes API de parcours de l'arbre DOM comme la propriété children.
| Propriété/Méthode | Description | ||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
childNodes |
Renvoie un tableau de tous les nœuds enfants de l'élément. | ||||||||||||||||||||||||||
firstChild |
Renvoie le premier nœud enfant de l'élément. | ||||||||||||||||||||||||||
getAttribute(nomAttribut) |
Renvoie la valeur de l'attribut spécifié. | ||||||||||||||||||||||||||
hasAttribute(nomAttribut) |
Renvoie une valeur booléenne précisant si le nœud courant a un attribut défini portant le nom spécifié. | ||||||||||||||||||||||||||
hasChildNodes() |
Renvoie une valeur booléenne précisant si le nœud courant a des nœuds enfants. | ||||||||||||||||||||||||||
lastChild |
Renvoie le dernier nœud enfant de l'élément. | ||||||||||||||||||||||||||
nextSibling |
Renvoie le nœud suivant directement le nœud courant. | ||||||||||||||||||||||||||
nodeName |
Renvoie le nom du nœud courant sous la forme d'une chaîne. | ||||||||||||||||||||||||||
nodeType |
Renvoie le type du nœud courant.
|
||||||||||||||||||||||||||
nodeValue |
Renvoie la valeur du nœud courant. Pour les nœuds contenant du texte, comme les nœuds texte et de commentaires, il s'agira de ce texte. Pour les nœuds d'attributs, leur valeur d'attribut. Pour tous les autres nœuds, null sera renvoyé. |
||||||||||||||||||||||||||
ownerDocument |
Renvoie l'objet document contenant le nœud courant. |
||||||||||||||||||||||||||
parentNode |
Renvoie le nœud parent du nœud courant. | ||||||||||||||||||||||||||
previousSibling |
Renvoie le nœud qui précède immédiatement le nœud courant. | ||||||||||||||||||||||||||
removeAttribute(nom) |
Retire l'attribut spécifié du nœud courant. | ||||||||||||||||||||||||||
setAttribute(nom, valeur) |
Définit la valeur de l'attribut spécifié avec sur le nœud courant. |
Internet Explorer a un comportement s'éloignant du standard, dans le sens où beaucoup de ces API ignoreront les nœuds comportant uniquement des espaces blancs, générés par exemple par les caractères de retour à la ligne. Mozilla ne les ignorera pas, il sera donc parfois nécessaire de les distinguer. Chaque nœud a une propriété nodeType indiquant le type de nœud. Par exemple, un élément aura le type 1, un nœud texte le type 3 et un nœud de commentaire le type 8. La meilleure manière de ne traiter que les nœuds d'éléments et de ne pas parcourir tous les nœuds enfants et de ne traiter que ceux dont l'attribut nodeType vaut 1 :
HTML:
<div id="foo">
<span>Test</span>
</div>
JavaScript:
var myDiv = document.getElementById("foo");
var myChildren = myXMLDoc.childNodes;
for (var i = 0; i < myChildren.length; i++) {
if (myChildren[i].nodeType == 1){
// nœud élément
};
};
Génération et manipulation de contenu
Mozilla supporte les anciennes méthodes d'ajout dynamique de contenu dans le DOM, comme document.write, document.open et document.close. Mozilla gère également la méthode innerHTML d'Internet Explorer, qui peut être appelée sur presque tous les nœuds. Il ne supporte cependant pas outerHTML (qui ajoute des balises autour d'un élément, et n'a pas d'équivalent standard) ni innerText (qui change la valeur textuelle du nœud, et qui peut être remplacée dans Mozilla par l'utilisation de textContent).
Internet Explorer dispose de plusieurs méthodes de manipulation du contenu qui ne sont pas standard et ne sont pas gérées par Mozilla, permettant de récupérer la valeur, d'insérer du texte et des éléments à côté d'un nœud, comme getAdjacentElement et insertAdjacentHTML. Le Tableau 3 montre comment manipuler le contenu avec le standard W3C et Mozilla, avec des méthodes disponibles sur tous les nœuds DOM.
| Méthode | Description |
|---|---|
appendChild(nœud) |
Crée un nouveau nœud enfant. Renvoie une référence à ce nouveau nœud. |
cloneNode(profond) |
Crée une copie du nœud depuis lequel la méthode est appelée, et renvoie cette copie. Si le paramètre profond vaut true, copie également tous les descendants du nœud. |
createElement(nomDeBalise) |
Crée et renvoie un nouveau nœud DOM orphelin (sans parent), du type d'élément spécifié par le paramètre nomDeBalise. |
createTextNode(valeurTexte) |
Crée et renvoie un nouveau nœud DOM orphelin de type texte avec la valeur spécifiée dans valeurTexte. |
insertBefore(nouveauNœud, nœudEnfant) |
Insère le nœud nouveauNœud avant le nœud nœudEnfant, qui doit être un enfant du nœud courant. |
removeChild(nœudEnfant) |
Retire le nœud nœudEnfant des enfants du nœud courant, et renvoie une référence vers ce nœud. |
replaceChild(nouveauNœud, nœudEnfant) |
Remplace le nœud nœudEnfant par nouveauNœud dans les nœuds enfants de l'élément courant et renvoie une référence vers le nœud retiré. |
Fragments de document
Pour des questions de performances, il est possible de créer des documents en mémoire plutôt que de travailler avec le DOM du document existant. Le DOM Level 1 Core propose pour cela les fragments de document, qui sont des documents légers contenant un sous-ensemble des interfaces d'un document normal. Par exemple, getElementById n'y existe pas, mais appendChild bien. Il est aisé d'ajouter des fragments de document à un document existant.
Mozilla permet de créer des fragments de document à l'aide de document.createDocumentFragment(), qui renvoie un fragment de document vide.
L'implémentation des fragments de document dans Internet Explorer, par contre, ne respecte pas les standards du W3C et renvoie simplement un document normal.
Différences concernant JavaScript
On attribue souvent la plupart des différences entre Mozilla et Internet Explorer à JavaScript. Pourtant, les problèmes concernent généralement les API que les navigateurs exposent via JavaScript, comme la gestion du DOM. Les deux navigateurs diffèrent très peu dans leur gestion du langage JavaScript ; les problèmes rencontrés sont souvent liés à la synchronisation.
Différences dans les dates en JavaScript
La seule différence concernant Date est la méthode getYear. Selon la spécification ECMAScript (qui est suivie par JavaScript), cette méthode ne passe pas l'an 2000, et l'exécution de new Date().getYear() en 2004 renvoie « 104 ». La spécification ECMAScript indique que getYear renvoie l'année moins 1900, ce qui était prévu à l'origine pour renvoyer « 98 » pour 1998. La méthode getYear a été rendue obsolète dans la troisième édition d'ECMAScript et remplacée par getFullYear(). Internet Explorer a modifié getYear() pour fonctionner comme getFullYear() et lui faire passer l'an 2000, tandis que Mozilla gardait le comportement standard.
Différences dans l'exécution de JavaScript
Les scripts JavaScript sont exécutés différemment selon le navigateur. Par exemple, le code suivant suppose que le nœud div existe déjà dans le DOM au moment où le bloc script est exécuté :
...
<div id="foo">Chargement…</div>
<script>
document.getElementById("foo").innerHTML = "Terminé.";
</script>
Cependant, il n'y a aucune garantie que ce soit le cas. Pour s'assurer que tous les éléments existent, il vaut mieux utiliser le gestionnaire d'évènement onload sur la balise <body> :
<body onload="terminer();">
<div id="foo">Chargement…</div>
<script>
function terminer() {
var element = document.getElementById("foo");
element.innerHTML = "Terminé.";
}
</script>
...
De tels problèmes de synchronisation peuvent également être liés au matériel — les systèmes plus lents peuvent révéler des bugs que des systèmes plus rapides auraient masqués. Un exemple concret est window.open, qui ouvre une nouvelle fenêtre :
<script>
function ouvrirFenetre(){
var myWindow = window.open("about:blank");
myWindow.location.href = "https://www.ibm.com";
}
</script>
Le problème dans ce code est que window.open est asynchrone — l'exécution de JavaScript n'est pas bloquée jusqu'à ce que l'ouverture de la fenêtre soit terminée. Par conséquent, la première ligne après l'appel à window.open peut être exécutée avant que la nouvelle fenêtre soit prête. Cette situation peut être traitée en disposant un gestionnaire onload dans la nouvelle fenêtre qui rappelle ensuite la fenêtre ouvrante (à l'aide de window.opener).
Différences dans la génération de HTML contenant du JavaScript
JavaScript est capable, au travers de document.write, de générer du HTML au fil de l'eau depuis une chaîne. Le problème principal se pose ici lorsque du JavaScript, intégré dans un document HTML (donc, à l'intérieur d'une balise <script>), génère du HTML contenant une balise <script>. Si le document est en mode de rendu strict, il analysera la balise </script> à l'intérieur de la chaîne comme la balise de fermeture pour la balise <script> externe. Le problème apparait plus clairement dans le code qui suit :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"https://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
...
<script>
document.write("<script type='text\/javascript'>alert('Hello');<\/script>")
</script>
Comme la page est en mode strict, le moteur d'analyse de Mozilla verra le premier <script> et continuera jusqu'à trouver une balise de fermeture, dans ce cas-ci le premier </script>. En effet, l'analyseur XHTML n'a aucune connaissance de JavaScript (ou tout autre langage) lorsqu'il est en mode strict. En mode quirks, l'analyseur fera attention au JavaScript pendant qu'il travaille (ce qui le ralentit). Internet Explorer est toujours en mode quirks, étant donné qu'il ne gère pas vraiment le XHTML. Pour que ça fonctionne en mode strict dans Mozilla, la chaîne doit être séparée en deux parties :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"https://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
...
<script>
document.write("<script type='text\/javascript'>alert('Hello');</" + "script>")
</script>
Débogage de JavaScript
Mozilla propose différentes manières de déboguer les problèmes liés à JavaScript dans les applications créées pour Internet Explorer. Le premier outil est la console JavaScript intégrée, montrée dans la Figure 1, où les erreurs et avertissements sont enregistrés. Elle est accessible dans Mozilla depuis le menu Outils -> Développement Web -> Console JavaScript ou dans Firefox (le navigateur simplifié de Mozilla) depuis Outils -> Console d'erreurs.
Figure 1. La console JavaScript
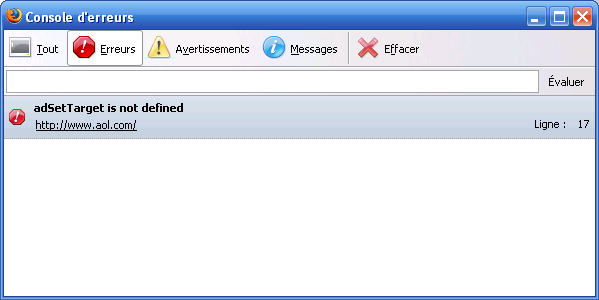
La console JavaScript peut afficher la liste complète des évènements enregistrés, ou juste les erreurs, avertissements et messages. Le message d'erreur dans la Figure 1 indique que sur le site aol.com, la ligne 17 essaie d'accéder à une variable non définie appelée adSetTarget. En cliquant sur le lien, la fenêtre interne de visualisation du code source de Mozilla s'ouvrira en surlignant la ligne concernée.
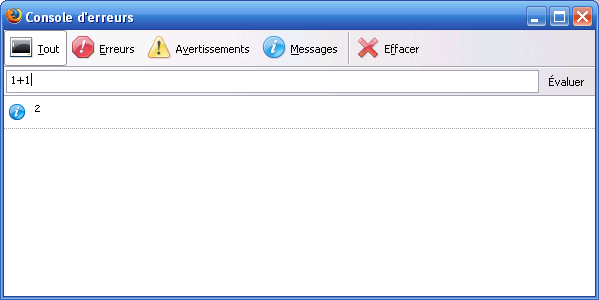
La console permet également d'évaluer du code JavaScript. Pour évaluer la syntaxe JavaScript entrée, introduisez 1+1 dans le champ et appuyez sur Évaluer, comme montré dans la Figure 2.
Figure 2. Évaluation dans la console JavaScript
Le moteur JavaScript de Mozilla intègre un support pour le débogage et peut donc servir de base à de puissants outils pour les développeurs JavaScript. Venkman, montré dans la Figure 3, est un débogueur JavaScript puissant et multiplateforme s'intégrant dans Mozilla. Il est généralement fourni avec les distributions de Mozilla et SeaMonkey ; il peut être trouvé dans Outils -> Développement Web -> Débogueur JavaScript. En ce qui concerne Firefox, le débogueur n'est pas fourni ; il peut être téléchargé et installé depuis la page du projet Venkman. Des tutoriels peuvent également être consultés sur la page de développement de Venkman. Toujours pour Firefox, vous trouverez un débogueur JavaScript intégré et d'autres outils de développement indispensables dans l'extension Firebug.
Figure 3. Le débogueur JavaScript de Mozilla
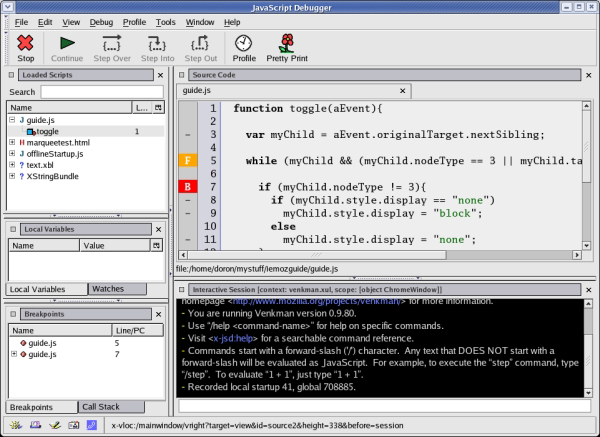
Le débogueur JavaScript peut traiter les scripts exécutés dans la fenêtre de navigation de Mozilla. Comme la plupart des débogueurs, il permet de gérer des points d'arrêt, d'inspecter la pile des appels et d'examiner des variables/objets. Toutes ces fonctionnalités sont accessibles depuis l'interface graphique ou la console interactive. Cette console permet d'exécuter des commandes JavaScript arbitraires dans le contexte du script en cours de débogage.
Différences concernant CSS
Les produits basés sur Mozilla ont un des meilleurs supports pour les feuilles de style en cascade (CSS), dont la plupart de CSS1, CSS2.1 et certaines parties de CSS3, lorsqu'on les compare à Internet Explorer ou d'autres navigateurs.
Pour la plupart des problèmes mentionnés ci-dessous, Mozilla signalera une erreur ou un avertissement dans la console JavaScript. Jetez un œil à la console JavaScript si vous rencontrez des problèmes liés aux CSS.
Types mime (lorsque les fichiers CSS ne sont pas chargés)
Le problème le plus courant lié aux CSS est la non application des définitions CSS présentes dans des fichiers référencés. La cause en est souvent l'envoi du mauvais type mime pour le fichier CSS par le serveur. La spécification CSS indique que les fichiers CSS doivent être servis avec le type mime text/css. Mozilla respectera cela et ne chargera que les fichiers CSS de ce type lorsqu'en mode de respect strict des standards. Internet Explorer chargera toujours le fichier CSS, quel que soit le type mime sous lequel il est servi. Les pages Web sont considérés comme étant en mode de respect strict des standards lorsqu'elles commencent par un doctype strict. Pour résoudre ce problème, vous pouvez faire en sorte que le serveur envoie le bon type mime, ou modifier ou retirer la déclaration doctype. Nous parlerons plus avant des doctypes dans la section suivante.
CSS et unités
Beaucoup d'applications Web n'utilisent pas d'unités au sein de leurs CSS, particulièrement lorsque JavaScript est utilisé pour définir ces CSS. Mozilla le tolère tant que la page n'est pas affichée en mode strict. Comme Internet Explorer ne supporte pas réellement XHTML, il ne se soucie pas de la présence d'unités ou non. Si la page est en mode de respect strict des standards, et qu'aucune unité n'est précisée, Mozilla ignorera le style :
<DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "https://www.w3.org/TR/html4/strict.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1"> <title>Exemple CSS et unités</title> </head> <body> // fonctionne en mode strict <div style="width: 40px; border: 1px solid black;"> Texte </div> // ne fonctionnera pas en mode strict <div style="width: 40; border: 1px solid black;"> Texte </div> </body> </html>
Comme l'exemple ci-dessus porte un doctype strict, la page sera rendue en mode de respect strict des standards. Le premier élément div aura une largeur de 40px, puisque les unités sont précisées, mais le second n'aura aucune largeur précise, et prendra donc la largeur par défaut de 100%. La même chose se produirait si la largeur était définie en JavaScript.
JavaScript et CSS
Comme Mozilla supporte les standards CSS, c'est également le cas pour le DOM CSS permettant de définir des styles CSS via JavaScript. Il est possible d'accéder à, retirer et modifier les règles CSS d'un élément via sa propriété membre style :
<div id="monDiv" style="border: 1px solid black;">
Texte
</div>
<script>
var monElm = document.getElementById("monDiv");
monElm.style.width = "40px";
</script>
Chaque attribut CSS peut être atteint de cette manière. À nouveau, si la page Web est en mode strict, vous devez préciser une unité ou Mozilla ignorera la commande. Lorsque la valeur d'une propriété est demandée, disons par .style.width, la valeur renvoyée dans Mozilla et Internet Explorer contiendra l'unité. Cela signifie qu'une chaîne est renvoyée. Celle-ci peut être convertie en un nombre grâce à parseFloat("40px").
Différences dans les débordements CSS
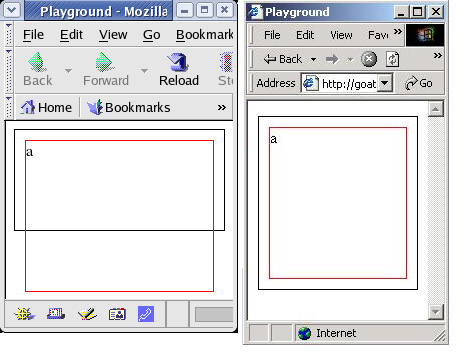
CSS ajoute la notion de débordement, qui permet de préciser comment traiter les dépassements de contenu ; par exemple, lorsque le contenu d'un élément div d'une hauteur précise est plus imposant que cette hauteur. Le standard CSS définit que si aucun comportement de débordement n'est précisé dans ce cas, le contenu du div débordera. Cependant, Internet Explorer ne respecte pas cela et étirera l'élément div au-delà de sa hauteur définie pour qu'il englobe tout son contenu. L'exemple ci-dessous illustre cette différence :
<div style="height: 100px; border: 1px solid black;">
<div style="height: 150px; border: 1px solid red; margin: 10px;">
a
</div>
</div>
Comme vous pouvez le voir dans la Figure 4, Mozilla se comporte comme spécifié dans le standard du W3C. Celui-ci précise que, dans ce cas, l'élément div intérieur déborde vers le bas puisque le contenu est plus haut que son élément parent. Si vous préférez le comportement d'Internet Explorer, il suffit de ne pas préciser de hauteur sur l'élément extérieur.
Figure 4. Débordement de DIV
Différences de survol (hover)
Le comportement non standard du survol CSS dans Internet Explorer s'illustre sur quelques sites Web. Il se manifeste généralement par un changement du style du texte lorsqu'il est survolé dans Mozilla, mais pas dans Internet Explorer. Ce comportement apparait parce que le sélecteur CSS a:hover dans Internet Explorer trouvera <a href="">...</a> mais pas <a name="">...</a>, qui permet de définir des ancres en HTML. Le changement du texte se produit lorsque les auteurs entourent certaines zones de balises définissant des ancres :
CSS:
a:hover {color: green;}
HTML:
<a href="foo.com">This text should turn green when you hover over it.</a>
<a name="anchor-name">
Ce texte devrait changer de couleur lorsqu'il est survolé, mais
cela n'arrive pas dans Internet Explorer.
</a>
Mozilla suit la spécification CSS et changera la couleur en vert dans cet exemple. Il existe deux manières d'obtenir le même comportement dans Mozilla que dans Internet Explorer pour ne pas changer la couleur du texte lorsqu'il est survolé :
- Tout d'abord, la règle CSS peut être changée pour devenir
a:link:hover {color: green;}, ce qui ne changera la couleur que si l'élément est un lien (dispose d'un attributhref). - Sinon, vous pouvez changer le balisage et fermer la balise
<a />avant le début du texte — l'ancre continuera à fonctionner.
Mode quirks et mode standard
Les anciens navigateurs, comme Internet Explorer 4, affichaient les pages de manière un peu étrange dans certaines conditions. Bien que Mozilla vise à être un navigateur respectueux des standards, il possède trois modes permettant d'afficher les pages plus anciennes créées autour de ces comportements particuliers. Le contenu de la page et son mode d'acheminement détermineront le mode utilisé par Mozilla. Mozilla indiquera son mode de rendu dans Affichage -> Informations sur la page (ou Ctrl+I) ; Firefox indiquera son mode de rendu dans Outils -> Informations sur la page. Le mode dans lequel une page est chargée dépend de son doctype.
Les déclarations doctype (déclarations de type de document) ressemblent à ceci :
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "https://www.w3.org/TR/html4/loose.dtd">
La partie en bleu s'appelle l'identificateur public, la partie en vert est l'identificateur système, qui est une URI.
Mode standard
Le mode standard est le mode de rendu le plus strict — il affichera les pages conformément aux spécifications HTML et CSS du W3C et n'acceptera aucune déviance. Mozilla l'utilise si une des trois conditions suivantes est remplie :
- Si la page est envoyée avec un type mime
text/xmlou tout autre type mime XML ou XHTML - Pour tout type de document "DOCTYPE HTML SYSTEM" (par exemple,
<!DOCTYPE HTML SYSTEM "https://www.w3.org/TR/REC-html40/strict.dtd">), à l'exception du doctype IBM - Pour les doctypes inconnus, ou sans DTD
Mode presque standard
Mozilla a ajouté un mode presque standard pour une raison particulière : une section de la spécification CSS 2 détruit les mises en page basées sur une disposition précise de petites images dans des cellules de tableaux. Au lieu de former une image aux yeux de l'utilisateur, chaque petite image est accompagnée d'un certain décalage. L'ancienne page d'accueil d'IBM montrée dans la Figure 5 en est un exemple.
Figure 5. Images décalées

Le mode presque standard se comporte presque exactement comme le mode standard, sauf en ce qui concerne les questions de décalage des images. Ce problème apparait souvent sur des pages respectant les standards et produit un affichage incorrect.
Mozilla utilise le mode presque standard dans les conditions suivantes :
- Pour tout doctype non strict (par exemple,
<!DOCTYPE HTML PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN">,<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "https://www.w3.org/TR/html4/loose.dtd">) - Pour le doctype IBM (
<!DOCTYPE html SYSTEM "https://www.ibm.com/data/dtd/v11/ibmxhtml1-transitional.dtd">)
Vous pourrez en savoir plus en lisant l'article sur les images décalées.
Mode quirks
Actuellement, le Web est rempli de balisages HTML invalides, ainsi que de balisages qui ne fonctionnent que grâce à des bugs dans les navigateurs. Les anciens navigateurs de Netscape, lorsqu'ils dominaient le marché, avaient des bugs. Lorsqu'Internet Explorer est arrivé, il a imité ces bugs afin de fonctionner avec le contenu disponible à l'époque. Chaque fois qu'un nouveau navigateur est arrivé sur le marché, la plupart de ces bugs, appelés quirks (bizarreries en anglais) ont été conservés pour rester compatible avec les anciennes pages. Mozilla en gère un grand nombre dans son mode de rendu quirks. Notez qu'à cause de ces « quirks », les pages sont affichées plus lentement que si elles respectaient les standards. La plupart des pages Web sont affichées dans ce mode.
Mozilla utilise le mode quirks aux conditions suivantes :
- Lorsqu'aucun doctype n'est précisé
- Pour les doctypes sans identificateur système (par exemple,
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">)
Pour en savoir plus, consultez les articles Comportement du mode quirks de Mozilla et Le sniffing de DOCTYPE dans Mozilla.
Différences dans la gestion des évènements
Mozilla et Internet Explorer diffèrent à peu près totalement dans leur gestion des évènements. Le modèle évènementiel de Mozilla suit celui du W3C et de Netscape. Dans Internet Explorer, si une fonction est appelée depuis un évènement, elle peut accéder à l'objet event depuis window.event. Mozilla passe un objet event aux gestionnaires d'évènements. Ils doivent passer spécifiquement l'objet en paramètre à la fonction appelée.
Voici un exemple de gestion d'évènement fonctionnant dans les deux navigateurs (notez que cela signifie que vous ne pourrez pas définir de variable globale appelée event dans votre) :
<div onclick="handleEvent(event);">Cliquez ici !</div>
<script>
function handleEvent(aEvent) {
var myEvent = window.event ? window.event : aEvent;
}
</script>
Les propriétés et fonctions exposées par l'objet event portent souvent des noms différents dans Mozilla et dans Internet Explorer, comme le montre le Tableau 4.
| Nom dans Internet Explorer | Nom dans Mozilla | Description |
|---|---|---|
altKey |
altKey |
Propriété booléenne indiquant si la touche Alt était enfoncée au cours de l'évènement. |
cancelBubble |
stopPropagation() |
Utilisé pour empêcher l'évènement de se propager plus haut dans l'arbre. |
clientX |
clientX |
La coordonnée X de l'évènement, relativement à la fenêtre de visualisation de l'élément. |
clientY |
clientY |
La coordonnée Y de l'évènement, relativement à la fenêtre de visualisation de l'élément. |
ctrlKey |
ctrlKey |
Propriété booléenne indiquant si la touche Ctrl était enfoncée au cours de l'évènement. |
fromElement |
relatedTarget |
Pour les évènements souris, il s'agit de l'élément depuis lequel le pointeur a bougé. |
keyCode |
keyCode |
Pour les évènements clavier, il s'agit d'un nombre représentant la touche pressée. Il vaut 0 pour les évènements souris. Pour les évènements keypress (pas keydown ou keyup) sur des touches produisant une sortie, l'équivalent dans Mozilla est charCode plutôt que keyCode. |
returnValue |
preventDefault() |
Utilisé pour empêcher l'action par défaut de l'évènement de se déclencher. |
screenX |
screenX |
La coordonnée X de l'évènement, relativement à l'écran. |
screenY |
screenY |
La coordonnée Y de l'évènement, relativement à l'écran. |
shiftKey |
shiftKey |
Propriété booléenne indiquant si la touche Majuscule était enfoncée au cours de l'évènement. |
srcElement |
target |
L'élément auquel l'évènement a été envoyé en premier lieu. |
toElement |
currentTarget |
Pour les éléments souris, il s'agit de l'élément vers lequel la souris s'est déplacée. |
type |
type |
Renvoie le nom de l'évènement. |
Accrochage de gestionnaires d'évènements
Mozilla permet d'attacher des évènements de deux manières différentes depuis JavaScript. La première, permise dans tous les navigateurs, est de définir des propriétés event directement sur les objets. Pour définir un gestionnaire d'évènement click, une référence à une fonction est passée à la propriété onclick de l'objet :
<div id="myDiv">Cliquez ici !</div>
<script>
function handleEvent(aEvent) {
// si aEvent vaut null, on est dans le modèle d'Internet Explorer,
// donc on utilise window.event.
var myEvent = aEvent ? aEvent : window.event;
}
function onPageLoad(){
document.getElementById("myDiv").onclick = handleEvent;
}
</script>
Mozilla permet également d'utiliser la manière standardisée par le W3C d'attacher des gestionnaires d'évènements à des nœuds DOM. On utilise pour cela les méthodes addEventListener() et removeEventListener(), tout en bénéficiant de la possibilité de définir plusieurs écouteurs pour le même type d'évènement. Chacune de ces deux méthodes a besoin de trois paramètres : le type d'évènement, une référence à une fonction et une valeur booléenne indiquant si l'écouteur doit traiter l'évènement dans sa phase de capture. Si cette valeur vaut false, seuls les évènements en cours de propagation seront traités. Les évènements W3C se déroulent en trois phases : une phase de capture, une phase sur l'objectif et une phase de propagation (bubbling). Chaque objet event dispose d'un attribut eventPhase indiquant la phase dans laquelle il se trouve (les indices débutent à 0). Chaque fois qu'un évènement est déclenché, il démarre depuis l'élément DOM le plus extérieur, celui que se trouve à la racine de l'arbre. Il parcourt ensuite le DOM en utilisant le chemin le plus court vers l'objectif, c'est alors la phase de capture. Lorsque l'évènement atteint son objectif, il passe dans la seconde phase. Il repart en suite à travers l'arbre DOM vers la racine ; c'est la troisième phase, dite de propagation (bubbling). Le modèle évènementiel d'Internet Explorer ne possède que cette troisième phase ; par conséquent, en définissant le troisième paramètre à false, on obtient un comportement semblable à celui d'Internet Explorer :
<div id="monDiv">Cliquez ici !</div>
<script>
function handleEvent(aEvent) {
// si aEvent vaut null, on est dans le modèle d'Internet Explorer,
// on récupère donc window.event.
var myEvent = aEvent ? aEvent : window.event;
}
function onPageLoad() {
var element = document.getElementById("monDiv");
element.addEventListener("click", handleEvent, false);
}
</script>
Un avantage de addEventListener() et removeEventListener() par rapport à la définition de propriétés est qu'il devient possible de placer plusieurs écouteurs pour le même évènement, chacun appelant une fonction différente. Par conséquent, le retrait d'un gestionnaire d'évènement nécessite les trois mêmes paramètres que pour son ajout.
Mozilla ne permet pas d'utiliser la méthode de conversion des balises <script> en gestionnaires d'évènements qui existe dans Internet Explorer, qui étend <script> avec des attributs for et event (voir le Tableau 5). Il ne permet pas non plus d'utiliser les méthodes attachEvent et detachEvent. À la place, il faut utiliser les méthodes addEventListener et removeEventListener. Internet Explorer ne supporte quant à lui pas la spécification d'évènements du W3C.
| Méthode d'Internet Explorer | Méthode de Mozilla | Description |
|---|---|---|
attachEvent(type, fonction) |
addEventListener(type, fonction, capture) |
Ajoute un gestionnaire d'évènement à un élément DOM. |
detachEvent(type, fonction) |
removeEventListener(type, fonction, capture) |
Retire un gestionnaire d'évènement d'un élément DOM. |
Édition de texte enrichi
Bien que Mozilla se flatte d'être un des navigateurs les plus respectueux des standards Web du W3C, il permet également d'utiliser des fonctionnalités non standard, comme innerHTML et l'édition de texte enrichi, lorsqu'aucun équivalent W3C n'existe.
Mozilla 1.3 a intégré une implémentation de la fonctionnalité designMode d'Internet Explorer, qui transforme un document HTML en un champ d'édition de texte enrichi. Une fois en mode d'édition, des commandes peuvent être exécutées sur le document via execCommand. Mozilla ne permet pas d'utiliser l'attribut contentEditable pour rendre n'importe quel contrôle modifiable. Vous pouvez par contre utiliser un élément iframe pour créer un éditeur de texte enrichi.
Différences dans l'édition de texte enrichi
Mozilla supporte la méthode standard W3C d'accès à l'objet document d'un iframe avec IFrameElmRef.contentDocument, tandis qu'Internet Explorer vous demande d'y accéder par document.frames["IframeName"] avant de pouvoir accéder à l'objet document :
<script>
function getIFrameDocument(aID) {
var rv = null;
// si contentDocument existe, on utilise la méthode W3C
if (document.getElementById(aID).contentDocument){
rv = document.getElementById(aID).contentDocument;
} else {
// IE
rv = document.frames[aID].document;
}
return rv;
}
</script>
Une autre différence entre Mozilla et Internet Explorer est le code HTML généré par l'éditeur de texte enrichi. Mozilla utilise CSS par défaut sur le balisage généré. Cependant, il vous permet de passer du mode CSS au mode HTML en utilisant la commande useCSS avec execCommand et de la passer indifféremment de true à false. Internet Explorer utilise toujours un balisage HTML.
Mozilla (CSS): <span style="color: blue;">Big Blue</span> Mozilla (HTML): <font color="blue">Big Blue</font> Internet Explorer: <FONT color="blue">Big Blue</FONT>
Voici une liste des commandes qui peuvent être passées à execCommand dans Mozilla :
| Nom de commande | Description | Paramètre |
|---|---|---|
bold |
Inverse l'attribut bold (gras) de la sélection. |
--- |
createlink |
Génère un lien HTML depuis le texte sélectionné. | L'URL à utiliser pour le lien |
delete |
Supprime la sélection. | --- |
fontname |
Change la police utilisée pour le texte sélectionné. | Le nom de la police à utiliser (par exemple Arial) |
fontsize |
Change la taille de police utilisée pour le texte sélectionné. | La taille de police à utiliser |
fontcolor |
Change la couleur de police utilisée pour le texte sélectionné. | La couleur à utiliser |
indent |
Décale le bloc dans lequel se trouve le curseur vers la droite. | --- |
inserthorizontalrule |
Insère une ligne horizontale (élément <hr>) à l'emplacement du curseur. | --- |
insertimage |
Insère une image à l'emplacement du curseur. | URL de l'image à utiliser |
insertorderedlist |
Insère une liste ordonnée (élément <ol>) à l'emplacement du curseur. | --- |
insertunorderedlist |
Insère une liste non ordonnée (élément <ul>) à l'emplacement du curseur. | --- |
italic |
Inverse l'attribut italique de la sélection. | --- |
justifycenter |
Centre le contenu à la ligne courante. | --- |
justifyleft |
Aligne à gauche le contenu à la ligne courante. | --- |
justifyright |
Aligne à droite le contenu à la ligne courante. | --- |
outdent |
Réduit le décalage vers la droite du bloc dans lequel se trouve le curseur. | --- |
redo |
Rétablit la dernière commande annulée. | --- |
removeformat |
Retire tout le formatage de la sélection. | --- |
selectall |
Sélectionne tout dans l'éditeur de texte enrichi. | --- |
strikethrough |
Inverse l'attribut barré du texte sélectionné. | --- |
subscript |
Convertit la sélection en indice. | --- |
superscript |
Convertit la sélection en exposant. | --- |
underline |
Inverse l'attribut souligné du texte sélectionné. | --- |
undo |
Annule la dernière commande exécutée. | --- |
unlink |
Enlève toute information de lien de la sélection. | --- |
useCSS |
Active ou désactive l'utilisation de CSS pour le balisage généré. | Valeur booléenne |
Pour plus d'informations, consultez L'édition de texte enrichi dans Mozilla.
Différences dans la gestion de XML
Mozilla un très bon support d'XML et des technologies liées, comme XSLT et les services Web. Il permet également d'utiliser quelques extensions non standard d'Internet Explorer comme XMLHttpRequest.
Gestion de XML
Comme dans le cas du HTML standard, Mozilla supporte la spécification DOM XML du W3C, qui permet de manipuler à peu près n'importe quel aspect d'un document XML. Les différences entre le DOM XML d'Internet Explorer et celui de Mozilla sont généralement causées par le comportement non standard d'Internet Explorer. La différence la plus commune est sans doute leur manière de gérer les nœuds texte constitués d'espaces blancs. Souvent, le XML généré contient des espaces entre les nœuds XML. Dans Internet Explorer, Node.childNodes ne renverra pas ces nœuds texte d'espaces blancs. Dans Mozilla, ils feront partie du tableau de résultats.
XML :
<?xml version="1.0"?>
<myXMLdoc xmlns:myns="https://myfoo.com">
<myns:foo>bar</myns:foo>
</myXMLdoc>
JavaScript :
var myXMLDoc = getXMLDocument().documentElement;
alert(myXMLDoc.childNodes.length);
La première ligne de JavaScript charge le document XML et accède à l'élément racine (myXMLDoc) à l'aide de documentElement. La seconde ligne affiche simplement le nombre de nœuds enfants. Selon la spécification du W3C, les espaces blancs et les nouvelles lignes fusionnent en un seul nœud texte s'ils se suivent. Pour Mozilla, le nœud myXMLdoc a trois enfants : un nœud texte contenant un retour à la ligne et deux espaces ; le nœud myns:foo ; et un autre nœud texte avec un retour à la ligne. Internet Explorer, cependant, ne respecte pas cela et renverra « 1 » dans le code ci-dessus, c'est-à-dire uniquement le nœud myns:foo. Par conséquent, pour parcourir les nœuds enfants sans prendre en compte les nœuds texte, il faut pouvoir distinguer de tels nœuds.
Comme mentionné plus haut, chaque nœud a une propriété nodeType représentant le type de nœud. Par exemple, un nœud d'élément est de type 1, tandis qu'un nœud de document est de type 9. Pour éviter les nœuds textes, vous devez regarder ceux qui sont de type 3 (nœud texte) et 8 (nœud de commentaire).
XML :
<?xml version="1.0"?>
<myXMLdoc xmlns:myns="https://myfoo.com">
<myns:foo>bar</myns:foo>
</myXMLdoc>
JavaScript :
var myXMLDoc = getXMLDocument().documentElement;
var myChildren = myXMLDoc.childNodes;
for (var run = 0; run < myChildren.length; run++){
if ( (myChildren[run].nodeType != 3) &&
myChildren[run].nodeType != 8) ){
// not a text or comment node
};
};
Consultez Gestion des espaces dans le DOM pour plus de détails et une solution possible.
Ilots de données XML (data islands)
Internet Explorer dispose d'une fonctionnalité non standard appelée XML data islands, permettant d'intégrer du XML à l'intérieur d'un document HTML à l'aide d'une balise HTML non standard <xml>. Mozilla ne gère pas ces ilots de données XML et les traite comme des balises HTML inconnues. Même s'il est possible d'accomplir la même chose en utilisant XHTML, ce n'est généralement pas une option, le support d'Internet Explorer pour XHTML étant faible.
Ilot de données XML dans IE :
<xml id="xmldataisland"> <foo>bar</foo> </xml>
Une solution fonctionnant dans les deux navigateurs est d'utiliser des analyseurs DOM (parsers) qui analyseront une chaîne contenant un document XML sérialisé pour le transformer en un document généré. Mozilla utilise l'objet DOMParser, qui reçoit la chaîne sérialisée et en fait un document XML. Dans Internet Explorer, on peut réaliser la même chose en utilisant ActiveX. L'objet créé par new ActiveXObject("Microsoft.XMLDOM") dispose d'une méthode loadXML pouvant recevoir une chaîne en paramètre depuis laquelle il pourra générer un document. Le code suivant montre comment faire :
var xmlString = "<xml id=\"xmldataisland\"><foo>bar</foo></xml>";
var myDocument;
if (window.DOMParser) {
// Ce navigateur semble connaitre DOMParser
var parser = new DOMParser();
myDocument = parser.parseFromString(xmlString, "text/xml");
} else if (window.ActiveXObject){
// Internet Explorer, on crée un nouveau document XML avec ActiveX
// et loadXML comme analyseur DOM.
myDocument = new ActiveXObject("Microsoft.XMLDOM");
myDocument.async = false;
myDocument.loadXML(xmlString);
} else {
// Not supported.
}
Consultez Utilisation de Data Islands XML dans Mozilla pour une approche alternative.
XMLHttpRequest
Internet Explorer permet d'envoyer et de récupérer des fichiers XML au travers de la classe XMLHTTP de MSXML, instanciable via ActiveX à l'aide de new ActiveXObject("Msxml2.XMLHTTP") ou new ActiveXObject("Microsoft.XMLHTTP"). Comme il n'existait pas de méthode standard de faire cela, Mozilla fournit la même fonctionnalité dans un objet JavaScript global XMLHttpRequest. Depuis sa version 7, Internet Explorer a adopté cet objet « natif » XMLHttpRequest. Un brouillon de travail du W3C a également été créé sur base de cet objet global.
Après instanciation de l'objet à l'aide de new XMLHttpRequest(), il est possible d'utiliser la méthode open pour spécifier le type de requête (GET ou POST) à utiliser, le fichier à charger, et si cela doit se faire de manière asynchrone ou non. Si l'appel est asynchrone, il faut donner à la propriété membre onload la référence à une fonction, qui sera appelée dès que la requête aura abouti .
Requête synchrone :
var myXMLHTTPRequest = new XMLHttpRequest();
myXMLHTTPRequest.open("GET", "data.xml", false);
myXMLHTTPRequest.send(null);
var myXMLDocument = myXMLHTTPRequest.responseXML;
Requête asynchrone :
var myXMLHTTPRequest; function xmlLoaded() { var myXMLDocument = myXMLHTTPRequest.responseXML; } function loadXML(){ myXMLHTTPRequest = new XMLHttpRequest(); myXMLHTTPRequest.open("GET", "data.xml", true); myXMLHTTPRequest.onload = xmlLoaded; myXMLHTTPRequest.send(null); }
Le Tableau 7 fournit une liste des méthodes et propriétés disponibles pour l'objet XMLHttpRequest dans Mozilla.
| Name | Description | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
void abort() |
Arrête la requête si elle est toujours en cours. | ||||||||||||
string getAllResponseHeaders() |
Renvoie tous les en-têtes de réponse dans une chaîne. | ||||||||||||
string getResponseHeader(string entete) |
Renvoie la valeur de l'en-tête spécifié. | ||||||||||||
functionRef onerror |
Si ce paramètre est défini, la fonction référencée sera appelée si jamais une erreur se produit au cours de la requête. | ||||||||||||
functionRef onload |
Si ce paramètre est défini, la fonction référencée sera appelée lorsque la requête aboutit et que la réponse a été reçue. Utilisé avec les requêtes asynchrones. | ||||||||||||
void open (string methode_HTTP, string URL)void open(string methode_HTTP, string URL, boolean async, string utilisateur, string motdepasse) |
Initialise la requête pour l'URL spécifiée, en utilisant la méthode HTTP GET ou POST. Pour envoyer la requête, appelez la méthode send() après initialisation. Si async vaut false, la requête sera synchrone, autrement elle restera asynchrone (comportement par défaut). Il est également possible de spécifier un nom d'utilisateur et un mot de passe pour l'URL fournie si nécessaire. |
||||||||||||
int readyState |
État de la requête. Valeurs possibles :
|
||||||||||||
string responseText |
Chaîne contenant la réponse. | ||||||||||||
DOMDocument responseXML |
Document DOM contenant la réponse. | ||||||||||||
void send(variant corps) |
Lance la requête. Si le paramètre body est défini, il est envoyé comme corps de la requête POST. body peut être un document XML ou un document XML sérialisé dans une chaîne. |
||||||||||||
void setRequestHeader(string entete, string valeur) |
Définit un en-tête de requête HTTP à utiliser dans la requête. Doit être appelée après l'appel à open(). |
||||||||||||
string status |
Le code d'état de la réponse HTTP. |
Différences concernant XSLT
Mozilla supporte la version 1.0 des transformation XSL (XSLT). Il permet également d'utiliser JavaScript pour effectuer des transformations XSLT et permet d'utiliser XPath sur un document.
Mozilla a besoin que les fichiers XML et XSLT soient envoyés avec un type mime XML (text/xml ou application/xml). C'est la raison la plus courante pour laquelle XSLT ne fonctionne pas dans Mozilla alors qu'il fonctionne avec Internet Explorer. Mozilla est strict dans ce domaine.
Internet Explorer 5.0 et 5.5 supportaient le brouillon de travail de XSLT, qui est sensiblement différent de la recommandation finale XSLT 1.0. La meilleure manière de savoir pour quelle version un fichier XSLT a été écrit est de regarder son espace de noms (namespace). L'espace de noms pour la recommandation XSLT 1.0 est https://www.w3.org/1999/XSL/Transform, tandis que celui du brouillon de travail était https://www.w3.org/TR/WD-xsl. Internet Explorer 6 gère toujours ce brouillon de travail pour pour des raisons de compatibilité, mais ce n'est pas le cas de Mozilla. Mozilla gère uniquement la recommandation finale.
Si votre XSLT a besoin de distinguer les navigateurs, vous pouvez utiliser la propriété système « xsl:vendor ». Le moteur XSLT de Mozilla s'identifiera comme "Transformiix" tandis qu'Internet Explorer renverra "Microsoft".
<xsl:if test="system-property('xsl:vendor') = 'Transformiix'">
<!-- Instructions spécifiques à Mozilla -->
</xsl:if>
<xsl:if test="system-property('xsl:vendor') = 'Microsoft'">
<!-- Instructions spécifiques à Internet Explorer -->
</xsl:if>
Mozilla fournit également des interfaces JavaScript pour XSLT, permettant à un site Web de réaliser des transformations XSLT en mémoire. Cela peut se faire en utilisant l'objet JavaScript global XSLTProcessor. XSLTProcessor a besoin que les fichiers XML et XSLT soient chargés, car il utilise leurs documents DOM. Le document XSLT, importé par XSLTProcessor, permet de manipuler les paramètres XSLT.
XSLTProcessor peut générer un document standalone à l'aide de transformToDocument(), ou créer un fragment de document avec transformToFragment() qui peut ensuite être ajouté facilement à un autre document DOM. Un exemple est fourni ci-dessous :
var xslStylesheet;
var xsltProcessor = new XSLTProcessor();
// charge le fichier xslt, example1.xsl
var myXMLHTTPRequest = new XMLHttpRequest();
myXMLHTTPRequest.open("GET", "example1.xsl", false);
myXMLHTTPRequest.send(null);
// récupère le document XML et l'importe
xslStylesheet = myXMLHTTPRequest.responseXML;
xsltProcessor.importStylesheet(xslStylesheet);
// charge le fichier xml, example1.xml
myXMLHTTPRequest = new XMLHttpRequest();
myXMLHTTPRequest.open("GET", "example1.xml", false);
myXMLHTTPRequest.send(null);
var xmlSource = myXMLHTTPRequest.responseXML;
var resultDocument = xsltProcessor.transformToDocument(xmlSource);
Après la création d'un XSLTProcessor, le fichier XSLT doit être chargé à l'aide de XMLHttpRequest. L'attribut membre responseXML de XMLHttpRequest contient le document XML du fichier XSLT, qui est passé à importStylesheet. On réutilise ensuite XMLHttpRequest pour charger le document XML source à transformer ; ce docuemnt est alors passé à la méthide transformToDocument de XSLTProcessor. Le Tableau 8 fournit une liste des méthodes de XSLTProcessor.
| Méthode | Description |
|---|---|
void importStylesheet(Node styleSheet) |
Importe la feuille de styles XSLT. Le paramètre styleSheet est le nœud racine du document DOM d'une feuille de style XSLT. |
DocumentFragment transformToFragment(Node source, Document owner) |
Transforme le nœud source en appliquant la feuille de styles importée par la méthode importStylesheet et génère un objet DocumentFragment. owner spécifie le document DOM auquel ce fragment doit appartenir, ce qui lui permettra d'être ajouté à ce document. |
Document transformToDocument(Node source) |
Transforme le nœud source en lui appliquant la feuille de styles importée par la méthode importStylesheet et renvoie un document DOM standalone. |
void setParameter(String namespaceURI, String localName, Variant value) |
Définit un paramètre dans la feuille de styles XSLT importée. |
Variant getParameter(String namespaceURI, String localName) |
Obtient la valeur d'un paramètre dans la feuille de styles XSLT importée. |
void removeParameter(String namespaceURI, String localName) |
Retire tous les paramètres définis de la feuille de styles XSLT importée et rétablit les paramètres par défaut pour XSLT. |
void clearParameters() |
Retire tous les paramètres définis et rétablit les paramètres par défaut spécifiés dans la feuille de styles XSLT. |
void reset() |
Retire tous les paramètres et toutes les feuilles de styles. |
Informations sur le document original
- Auteur(s) : Doron Rosenberg, IBM Corporation
- Publié le : 26 juillet 2005
- Lien : https://www.ibm.com/developerworks/we...y/wa-ie2mozgd/